Simulation
Comparing Systems, Continued
30 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Comparing Systems, Continued
Normal Means Selection
In this lesson, we will look at the classic problem of choosing the normal distribution having the largest mean. Furthermore, we'll guarantee a certain probability of correct selection.
Find the Normal Distribution with the Largest Mean
Let's start with some underlying assumptions. We will assume that we can take independent observations, , from normal populations . Here, refers to a normal distribution with unknown mean and known or unknown variance .
Let's denote the vector of means as and the vector of variances as . Furthermore, let's denote the ordered (but unknown) 's as .
We will refer to the "best" system as that which has the largest mean, . Our goal is to select the population - strategy, treatment, alternative, etc. - associated with mean . We make a correct selection (CS) if we achieve our goal.
Indifference-Zone Probability Requirement
For specified constants, and , where and we require:
We want the probability of correct selection to be at least , which we specify according to our sensitivity. Moreover, is in the range . The lower bound is , not zero, because is the probability of correct selection given a random guess. Of course, cannot equal one unless we take an infinite number of samples.
On the other hand, merely has to be greater than zero, because its a bound on , and . Remember, we also specify .
We can think about as the smallest difference worth detecting. When we specify a small , we are saying that we want to catch very small differences between and . As we increase , we increase the difference between and that we are willing to tolerate.
As long as the difference between the two values is less than , we don't care which we pick. Of course, if the difference between and is bigger than , we want to make sure we select the right population.
Obviously, the probability of correct selection depends on the differences , the sample size, , and .
Parameter configurations satisfying the constraint are in the preference zone for correct selection. For example, if , , and , then the containing this and would be in the preference zone.
If falls in the preference zone, we want to ensure that we make the correct selection.
Parameter configurations not satisfying the constraint are in the indifference zone. For example, if , , and , then the containing this and would be in the indifference zone.
If falls in the indifference zone, it doesn't matter too much if we choose over , because the two values are within the threshold we've set.
Any procedure that guarantees equation above is said to be employing the indifference zone approach.
So Many Procedures
There are hundreds of different procedures we can use that implement this approach. Of note are the following:
- Bechhofer's Single-Stage procedure
- Rinott's Two-Stage procedure
- Kim and Nelson's Sequential procedure
We'll look at the basics of the single-stage procedure in the next lesson. As a word of caution, we wouldn't use this procedure in the wild. It relies on common, known variances among the competing populations, and we rarely know variances when running experiments.
Single-Stage Normal Means Procedure
In this lesson, we'll look at a specific, simple single-state procedure. The purpose of this light introduction is to give a taste of the kinds of procedures available for these types of general selection problems. As we said previously, this procedure assumes that all of the competing normal distributions have common, known variances, which is almost always an unrealistic assumption. Better procedures are out there.
Single-Stage Procedure
The single-stage procedure, , from Bechhofer, takes all necessary observations and makes a selection decision at once. It assumes that the populations have common, known variance, which is a fairly restrictive assumption.
For competing populations, with specified and , we determine a sample size , usually from a table, such that our probability requirement is satisfied. Remember that and are the previously discussed parameters, and is the known standard deviation.
Once we have , we will take a random sample of observations in a single stage from .
We then calculate the sample means:
We will select the population that yields the largest sample mean, as the one associated with .
The procedure is very intuitive. All that remains is to figure out . We can use a table or a multivariate normal quantile, or we can compute via a separate simulation if all else fails.
Let's take a look at the table:
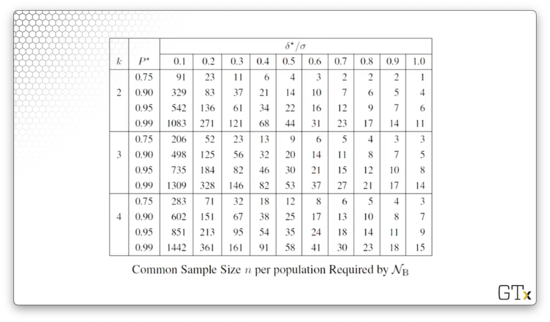
We can see the various parameters along the left and top axes, and the required value for in the corresponding cell. For instance, if we have competitors, and we want the probability of correct selection to be , and we want , then we'll take observations.
If we don't want to use the table, we can directly calculate using a multivariate normal quantile:
Let's remember our probability requirement:
The value of satisfies the above requirement for any vector of unknown means, , having the following configuration:
This configuration is known as the slippage, or least-favorable, configuration. All of the inferior means are the same, and the best mean is better than the rest. This configuration is least-favorable because, for fixed , it minimizes among all in the preference zone.
Proof
Let's look at a proof of how we calculate . Let's start by defining as the probability of correct selection given that we are in the least-favorable configuration:
The correct selection is that population that has the true best mean. We can only make the correct selection if the sample mean corresponding to the true best mean is bigger than all the other sample means. Assuming the true best population is the th one:
If we select population , we better make sure that its sample mean is larger than the sample means from all other competing populations.
Let's standardize the right-hand side of the inequality by subtracting its true mean, , whatever that may be, and dividing by its variance, . Of course, we have to apply the same transformation to the left-hand side:
We know that the right-hand side of the inequality is a standard normal random variable. Let's call that now. We can condition it out by integrating over all . Notice that we have to include the standard normal pdf, , in this integration:
Now, let's standardize the right-hand side of the inequality. We can't just subtract by since we are already subtracting by , so we have to add an adjustment factor on the right-hand side:
Now we are dealing with the cdf of a standard normal random variable, by definition. Therefore:
Since the observations are independent, and we have of them, we have to multiply the expression together times. That's why we have the notation.
If we set , then:
Finally, we solve numerically for and set .
Example
Suppose , and we want to detect a difference in means as small as standard deviations with . The table for calls for observations per population.
If, after taking observations, we find that , , , and , then we select population three as the best. Since population three has the largest sample mean, we state that it has the largest true mean.
Note that increasing or decreasing requires a smaller . For example, when and , then only requires observations per population.
Normal Means Extensions (OPTIONAL)
In this lesson, we'll look at some extensions of Bechhofer's single-stage procedure. As we saw, Bechhofer's procedure is rather limited and only applies to rare situations in which the systems share a common, known variance.
Good News
Bechhofer's single-stage procedure is very easy and intuitive. As we discussed, we look up in a table the number of observations, , that we need to take for each of competing systems based on parameters and . After taking observations, we select the population with the largest sample mean. With a probability of at least , that population will have the largest true mean.
As it turns out, this procedure is robust against certain assumption violations. For example, if we are sampling exponential data instead of normal data, we might still be able to use this procedure. However, if the observations are dependent, this procedure does not work well.
Bad News
Unfortunately, this procedure does have some drawbacks. For example, the assumption that the variances are common and known almost renders the procedure unusable in the real world since we rarely, if ever, know the variances of the populations we are studying.
Furthermore, this procedure is conservative in that we typically require too many observations to do the job. The procedure is designed to work for the least-favorable configuration. Sometimes, one population is so superior that we are in better shape than the least favorable configuration. In these "more-favorable" configurations, we could achieve with fewer samples than the table specifies.
The procedure also requires the competing populations to be independent. This requirement is not necessarily valid when we have simulation data, so we have to be careful.
What to Do?
Any real-life problem will most likely involve unknown and unequal variances among the populations. Thankfully, there are procedures that we can use.
We might use a technique like Rinott's two-stage procedure. This procedure estimates the variances of the populations in the first stage of sampling. This stage of observations determines how many observations are required in stage two to get the desired probability of correct selection.
Kim and Nelson's sequential procedure is probably the most-used contemporary procedure. In stage one, the procedure estimates variances, just like Rinott's does. Then, the procedure samples from the competing populations in multiple stages and eliminates those that aren't performing highly as sampling proceeds.
These procedures obviously require iid normal observations within each system, so we likely cannot apply them to simulation data. For example, random variables such as consecutive waiting times are correlated and nonnormal.
Instead of consecutive waiting times, we can take batches of waiting times and work with the batch means, which are approximately normal and independent for sufficiently large batch size.
We usually require that competing systems be independent. However, various procedures exist that allow us to work with correlated systems. We can leverage these procedures in simulations where we can induce a positive correlation between systems. If handled properly, correlation can help determine which competing system is the best.
Bernoulli Probability Selection
In this lesson, we'll talk about selecting the Bernoulli population with the largest success parameter.
Bernoulli Selection - Introduction
Our goal is to select the Bernoulli population with the largest success parameter from several competing systems. For example, we might want to select:
- the most effective anti-cancer drug
- the simulated system that is most likely to meet a design specification
- the (s,S) inventory policy with the highest profit probability
There are hundreds of such procedures for selecting the correct Bernoulli population. Of note are:
- Single-Stage Procedure (Sobel and Huyett 1957)
- Sequential Procedure (Bechhofer, Kiefer, and Sobel 1968)
- Optimal Procedures (Bechhofer et al., 1980's)
We have competing Bernoulli populations with unknown success parameters . We denote the ordered 's by . Our goal is to select the population having the largest probability .
As in previous lessons, we will again specify a formal probability requirement. For specified constants, , where and , we require:
This requirement states that whenever there is a large difference between the best and second-best system - greater than or equal to - we want to ensure that we make the right choice, with probability .
A Single-Stage Procedure
Let's look at the single-stage procedure, , from Sobel and Huyett.
For specified , we find in the table. Here's the table:
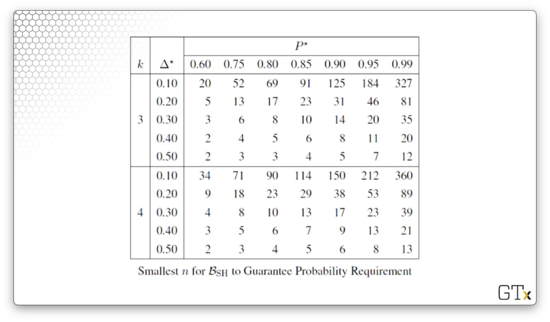
Next, we take a sample of observations, , in a single stage from each population . From there, we calculate the sample sums:
In plain English, represents the number of successes from the th population under study. We then select the treatment that yielded the largest as the one associated with . If there happens to be a tie, we select a random winner among the ties.
Example
Suppose we want to select the best of treatments. We want to be correct with probability of at least whenever . The table shows that we need observations from each population to meet this requirement.
Suppose that, at the end of sampling, we have the following success counts:
Then we select population two as best.
Bernoulli Extensions (OPTIONAL)
In this lesson, we will look at extensions of the Bernoulli procedure from the previous lesson. These extensions will save us many observations.
Curtailment
Let's look at a single-stage extension from Bechhofer and Kulkarni called curtailment. Here, we carry out the single-stage procedure, except we stop sampling when the population in second place can at best tie. It doesn't make sense to take any more observations after a winner is guaranteed.
As it turns out, curtailment gives the same probability of correct selection, , but with a lower expected number of observations, .
For example, remember that, when , , and , the single-stage procedure requires us to take observations from each population, for a total of observations.
Suppose that, after taking 180 samples from each population, we have the intermediate result , , , and .
We can stop sampling right now and select population two as the best because it's not possible for population four to catch up in the remaining observations. At best, .
A Sequential Procedure
An even better procedure is the sequential procedure, , by Bechhofer, Kiefer, and Sobel from 1968.
This procedure involves a new probability requirement. For specified , with and , we require whenever the odds ratio:
Here, we are taking the ratio of the odds that the th population is the best over the odds that the th population is the best. Whenever that ratio is , we want to ensure that the probability of correct selection is at least .
The procedure proceeds in stages. We take one Bernoulli observation from each population, and we reevaluate to see if the odds ratio satisfies our requirement. This method is even more efficient than curtailment, which is more efficient than the basic single-stage procedure.
Let's take a look at the procedure itself. At the th stage of experimentation, , we observe the random Bernoulli vector, . For example, if we are looking at populations, the vector might look like .
Next, we compute the population sums so far:
Then, we order the sums:
We stop at stage if the following inequality holds:
If the difference is large, for all , then raised to that power will be small, and the summation is likely to be less than . In other words, we stop when the best population is sufficiently ahead of the remaining populations.
Let's let be the random stage when the procedure stops. Then, we select the population yielding as the one associated with .
For example, let and . Suppose we obtain the following sequence of vector-observations using :
Given , we stop when . After the round of sampling, we get , and we choose the population with the largest as the one associated with . In this case, we choose population three.
Multinomial Cell Selection
In this lesson, we will talk about the multinomial selection problem, which corresponds to the problem of finding the most-probable category. This selection problem has applications in surveys, simulations, and more.
Multinomial Selection - Intro
We want to select the multinomial cell (category) having the largest probability. For example:
- Who is the most popular political candidate?
- Which television show is most-watched during a particular time slot?
- Which simulated warehouse configuration is most likely to maximize throughput?
These questions are different than the Bernoulli examples we looked at previously. In those examples, the populations succeeded or failed independently of one another. In this case, the various cells are competing against each other.
Yet again, we will take the indifference-zone approach, albeit in a slightly different way than in the binomial procedure.
Here's the experimental setup. We have possible outcomes. The probability that we will select a given category, , as being the most probable is . We will take independent replications of the experiment and let equal the number of outcomes falling in category after taking the observations.
Let's look at a definition. Suppose we have a -variate discrete vector random variable with the following probability mass function:
If has the probability mass function, then has the multinomial distribution with parameters and , where and for all . The multinomial generalizes the binomial.
Example
Suppose three of the faces of a fair die are red, two are blue, and one is violet. Therefore . Let's toss the die times. Then the probability of observing exactly three reds, no blues, and two violets is:
Now suppose that we did not know the probabilities for red, blue, and violet, and we want to select the most probable color. Using the selection rule, we choose the color the occurs the most frequently during the five trials, using randomization to break ties.
Let denote the number of occurrences of (red, blue, violet) in five trials. The probability we correctly select red is:
Notice that we have a coefficient of 0.5 in front of the cases where red ties because we randomly break two-way ties, selecting each color with a probability of 0.5.
We can list the outcomes favorable to a correct selection of red, along with the associated probabilities (calculated using the multinomial pmf above), randomizing in case of ties:
As we can see, in this case, the probability of correct selection is 0.6042, given observations. We can increase the probability of correct selection by increasing .
Example 2
The most probable alternative might be preferable to that having the largest expected value. Consider two inventory policies, and . The profit from is $5 with probability one, and the profit from is $0 with probability 0.99 and $1000 with probability 0.01.
The expected profit from is $5 and the expected profit from is $10: . However, the actual profit from is better than the profit from with probability 0.99. Even , wins almost all of the time.
Multinomial Procedure & Extensions
In this lesson, we'll look at the single-stage procedure for selecting the most-probable cell along with a few extensions.
Assumptions and Notation for Selection Problem
Let's let be independent observations taken from a multinomial distribution having categories with associated unknown probabilities .
For a fixed , refers to one multinomial observation, which is of length , corresponding to each of the categories. For example, if we have political candidates to choose from, has entries.
The entry equals one if category occurs on the th observation. Otherwise, . For example, if we ask someone to choose from eight different candidates, and they choose candidate one, then and .
We can order the underlying, unknown 's like so: . The category with is the most probable or best category.
We will survey many people and count up the number of times they select each category. The cumulative sum for category after we take multinomial observations is:
The ordered 's are . We select the candidate associated with as being associated with .
Our goal in this problem is to select the category associated with , and we say that a correct selection is made if the goal is achieved. For specified , where and , we have the following probability requirement:
When the ratio of the best category to the second-best category eclipses a certain that we specify, we want to ensure that we make the right selection with at least probability . We can interpret as the smallest ratio worth detecting.
Single-Stage Procedure
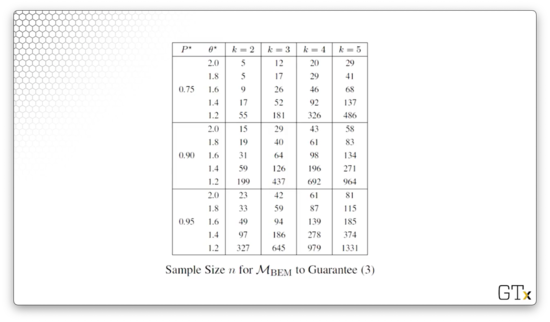
Let's look at the single-stage procedure, , by Bechhofer, Elmaghraby, and Morse, from 1959. For a given , , and , we find the required number of multinomial observations, , from a table.
First, we take multinomial observations in a single stage. From there, we calculate the ordered sample sums, . Finally, we take the category with the largest sum, as the one associated with , randomizing to break ties.
The -values are computed so that achieves when the cell probabilities are in the least-favorable configuration:
In this configuration, the best category is ahead of all of the other categories by a factor of exactly , and the other 's are all identical.
In any event, here is the table, parameterized by , , and that guarantees the appropriate probability of correct selection.
Example
A soft drink producer wants to find the most popular of proposed cola formulations. The company will give a taste test to people. The sample size is to be chosen so that whenever the ratio of the largest to second largest true (but unknown) proportions is at least 1.4.
From the table, we see that, for , , and , we need to take multinomial observations. Let's take those observations and assume that we find , , and . Then, we select formulation two as the best.
Extensions
We can use curtailment in multinomial cell selection and stop sampling when the category in second place cannot win. Additionally, we can use a sequential procedure and take observations one at a time until the winner is clear.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy