Operating Systems
Threads And Concurrency
27 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Threads And Concurrency
Process vs. Thread
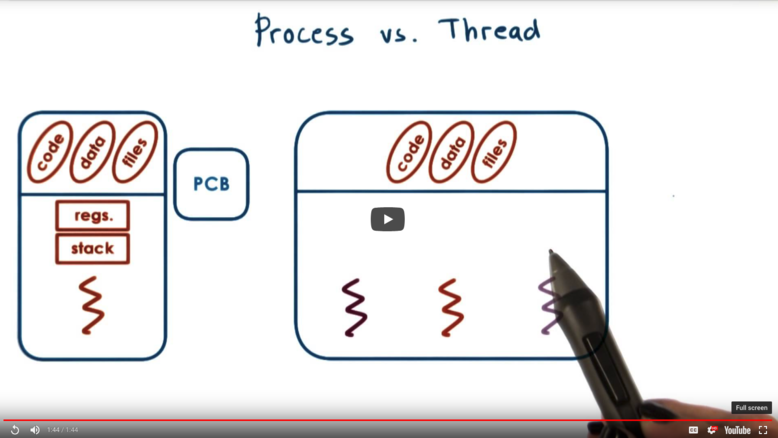
A single-threaded process is represented by two components:
- address space (virtual <-> physical memory mapping) code data * heap
- execution context CPU registers stack
All of this information is represented by the operating system in a process control block.
Threads represent multiple independent execution contexts within the same address space, which means they share the virtual to physical address mapping, as well as the code/data/files that make up the application.
However, they will potentially be running different instructions and accessing different portions of the address space at any given time. This means that each thread will have to have its own registers and stack.
Each and every thread has its own data structure to represent information specific to its execution context.
A multithreaded process will have a more complex process control block structure, as these thread specific execution contexts need to be incorporated.
Benefits of Multithreading
At any given time when running a multithreaded process on a multiprocessor machine, there may be multiple threads belonging to that process, each running on a given processor. While each thread is executing the same code (in the sense of same source code), each thread may be executing a different instruction (in the sense of different line or function) at any given time.
As a result, different threads can work in parallel on different components of the program's workload. For example, each thread may be processing a different component of the program's input. By spreading the work from one thread/one processor to multiple threads that can execute in parallel on multiple processors, we have been able to speed up the program's execution.
Another benefit that we can achieve through multithreading is specialization. If we designate certain threads to accomplish only certain tasks or certain types of tasks, we can take a specialized approach with how we choose to manage those threads. For instance, we can give higher priority to tasks that handle more important tasks or service higher paying customers.
Performance of a thread depends on how much information can be stored in the processor cache (remember - cache lookups are super fast). By having threads that are more specialized - that work on small subtasks within the main application - we can potentially have each thread keep it's entire state within the processor cache (hot cache), further enhancing the speed at which the thread continuously performs it task.
So why not just write a multiprocess application?
A multiprocess application requires a new address space for each process, while a multithreaded application requires only one address space. Thus, the memory requirements for a multiprocess application are greater than those of a multithreaded application.
As a result, a multithreaded application is more likely to fit in memory, and not require as many swaps from disk, which is another performance improvement.
Also, passing data between processes - inter process communication (IPC) - is more costly than inter thread communication, which consists primarily of reading/writing shared variables.
Benefits of Multithreading: Single CPU
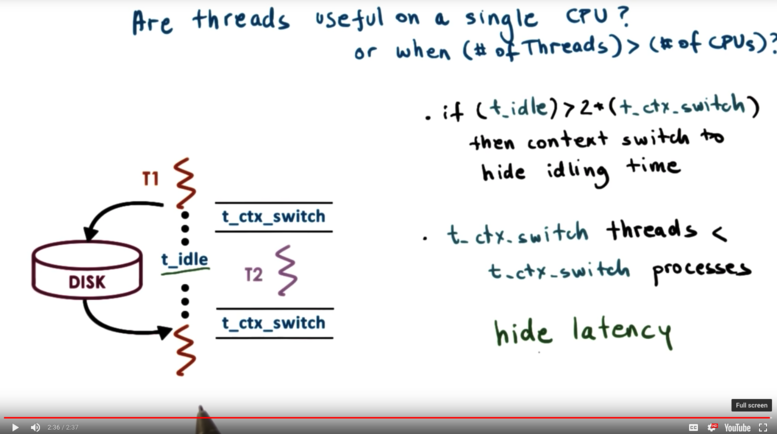
Generally, are threads useful when the number of threads exceeds the number of CPUs?
Consider the situation where a single thread makes a disk request. The disk needs some amount of time to respond to the request, during which the thread cannot do anything useful. If the time that the thread spends waiting greatly exceeds the time it takes to context switch (twice), then it makes sense to switch over to a new thread.
Now, this is true for both processes and threads. One of the most time consuming parts of context switching for processes is setting up the virtual to physical mappings. Thankfully, when we are context switching with threads, we are using the same mappings because we are within the same process. This brings down the total time to context switch, which brings up the number of opportunities in which switching threads can be useful.
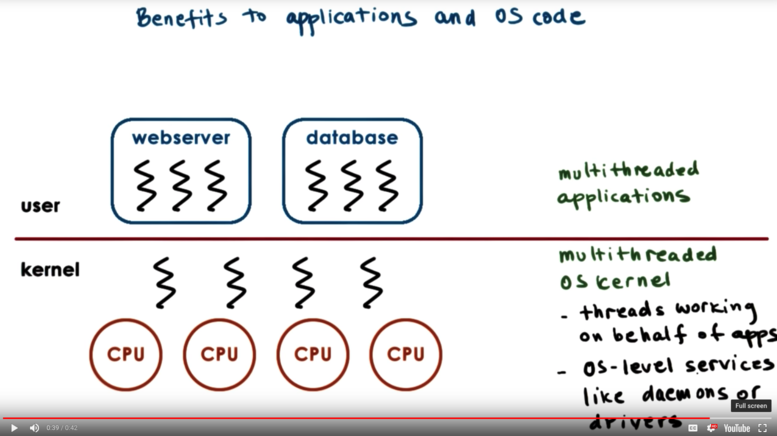
Benefits of Multithreading: Apps and OS Code
By multithreading the operating system kernel, we allow the operating system to support multiple execution contexts, which is particularly useful when we do have multiple CPUs, which allows the execution contexts to operate concurrently. The OS threads may run on behalf of different application or OS-level services like daemons and device drivers.
Basic Thread Mechanisms
When processes run concurrently, they operate within their own address space. The operating system ensures that physical access from one address space never touch memory mapped to by another process's address space.
Threads share the same virtual to physical address mappings, since they share the same address space. Naturally, this can introduce some problems. For example, one thread can try to read the data while another modifies it, which can lead to inconsistencies. This is an example of a data race problem.
To avoid such problems, we need a mechanism that allows threads to operate on data in an exclusive manner. We call this mutual exclusion. This is a mechanism by which only one thread at a time is granted access to some data. The remaining threads must wait their turn. We accomplish mutual exclusion through the use of a mutex.
Also, it is useful to have a mechanism by which a thread can wait on another thread, and to be able to exactly specify what condition the thread is waiting on. For this inter thread communication, we may use a construct called a condition variable.
Both mutexes and condition variables are examples of synchronization mechanisms.
Thread Creation
We need some data structure to represent a thread. The information we need to describe a thread may include:
- Thread ID
- Program counter
- Stack pointer
- Register values
- Stack
- Other attributes (priority attributes, etc.)
To create a thread, think of a fork (not the UNIX fork) call which takes two arguments - the proc to run when the thread is created, and the args to pass to proc.
When one thread calls fork a new thread is created, with a new data structure and its program counter pointing to the first argument of proc.
After the fork completes, the process now has two threads both of which can execute concurrently.
When the forked thread completes, we need some mechanism by which it can return its result or communicate its status to the forking thread. On the other hand, we need to ensure that a forking thread does not exit before its forked thread completes work (as child threads exit when parent threads do).
One mechanism that can handle this is the join mechanism. When the parent thread calls join with the thread id of the child it will be blocked until the child thread is finished processing. join returns the result of the child's computation. When join returns, the child thread exits the system and all resources associated with it are deallocated.
Thread Creation Example

NB: because we do not know which thread will run at which time in this example, we cannot be certain of the ordering of the elements in the list. Perhaps the child thread inserts its element before the parent thread, or perhaps the parent thread inserts first. This is a concrete example of the data race described above.
Mutexes
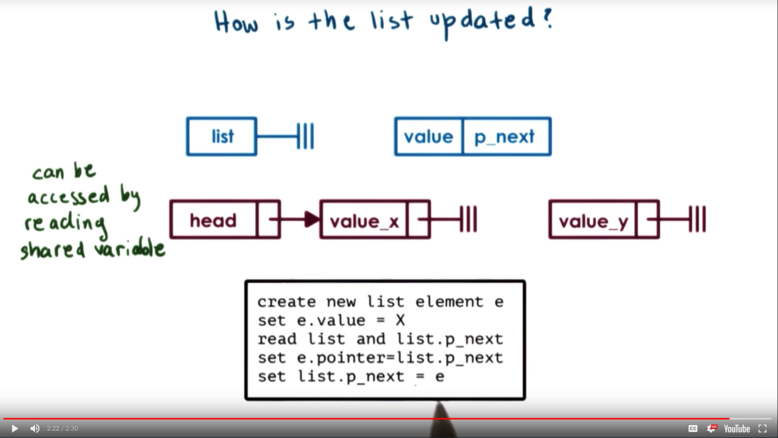
Many steps are required to add an element to the list. Think about two threads - A and B - trying to insert elements into the list. Here is a problematic scenario that can occur.
- Thread A reads
listandlist.p_next - Thread B reads
listandlist.p_next - Thread A sets
e.pointertolist.p_next - Thread B sets
e.pointertolist.p_next - Thread A sets
list.p_nexttoe - Thread B sets
list.p_nexttoe
When Thread A sets the value of list.p_next to it's element e, Thread B's reference to list becomes stale! When Thread B sets the value of list.p_next (where list does not refer to the new element added by Thread A), B essentially "splices out" the value that A just inserted!
Generally, when reading and writing to shared variables (in multiple steps, as is often the case), the opportunities for this type of data overwriting increase.
Mutual Exclusion
To support mutual exclusion, operating systems support a construct called a mutex. A mutex is like a lock that should be used whenever you access data/state that is shared among threads. When a thread locks a mutex, it has exclusive access to the shared resource. Other threads attempting to lock the same mutex will not be successful. These threads will be blocked on the lock operation, meaning they will not be able to proceed until the mutex owner releases the mutex.
As a data structure, the mutex should have at least the following information:
- lock status
- owner
- blocked threads
The portion of the code protected by the mutex is called the critical section. The critical section should contain any code that would necessitate restricting access to one thread at a time: commonly, providing read/write access to a shared variable.
Threads are mutually exclusive with respect to their execution of the critical section of the code. That is, the critical section will ever only be executed by one thread at a given moment in time.
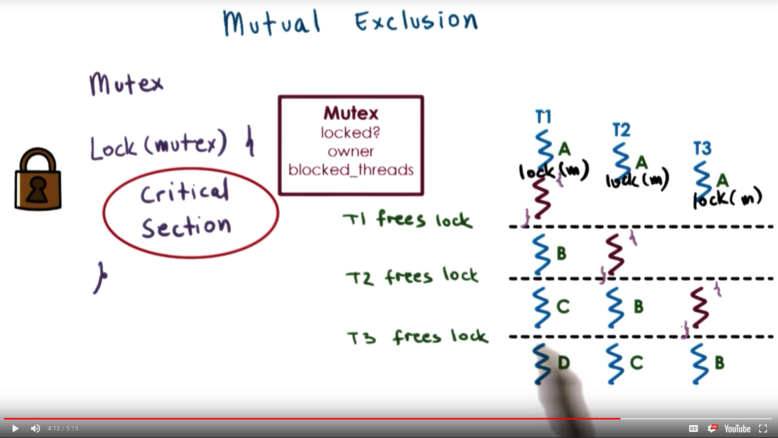
The mutex can be unlocked in two ways, depending on the implementation:
- the end of a clause following a lock statement is reached
- an unlock function is explicitly called
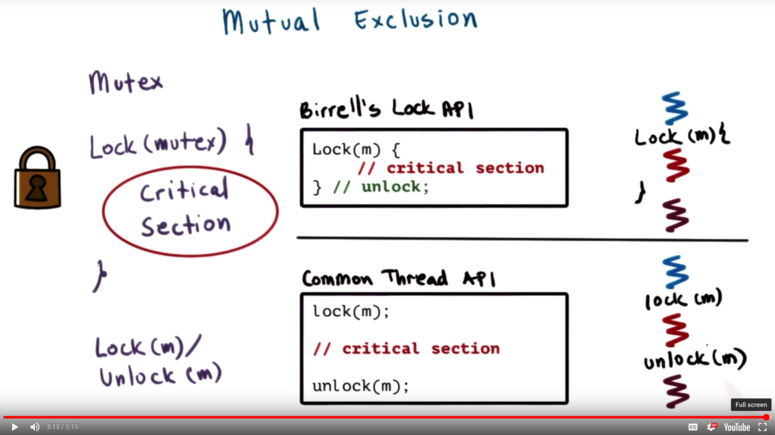
Mutex Example

Producer and Consumer Example
Mutual exclusion is a binary operation: either the lock is free and the resource can be accessed, or the lock is not free and the resource cannot be accessed.
What if the processing you wish to perform needs to occur with mutual exclusion, but only under certain conditions?
For example, what if we have a number of producer threads adding values to a list, and one consumer thread that needs to wait until, say, the list is full? We want to ensure that the consumer thread executes only when the condition is met.

Note that this strategy is kind of wasteful. Ideally we wouldn't want our consumer thread to loop but rather our producers to be able to notify the consumer when the list is full.
Condition Variables
A condition variable is a construct that can be used in conjunction with mutexes to control the execution of concurrent threads.

When a consumer sees that it must wait, it makes a call to the wait function, passing in a mutex and the condition variable it must wait on.
The wait function must ensure that the mutex is released if the condition is not met (so that the signaling thread may acquire the mutex) and must also ensure that the mutex is acquired when the condition is met (since the wait call occurs in the middle of a critical section).
When the condition becomes true, a thread holding the mutex may call the signal function to alert a waiting thread that they may proceed.
Condition Variable API
We need some type that corresponds to the condition variable. The condition variable data structure should contain:
- mutex reference
- list of waiting threads
We need a wait procedure which takes in a mutex and a condition variable. The wait procedure must be able to immediately release and reacquire the mutex as necessary depending on the condition variable.
We need a signal procedure, which allows a thread to signal to another thread waiting on a condition that the condition has been met.
We can also have a broadcast procedure, which allows a thread to signal to all other threads waiting on a condition that the condition has been met.
Basic implementation of wait procedure:
Wait(mutex, cond){
// atomically release mutex and place thread on wait queue
// wait wait wait
// remove thread from wait queue
// reacquire mutex
// exit wait
}Note that broadcast may not always be super useful. Even though we can wake up all threads in wait, since we immediately lock the mutex when we remove a thread from the wait queue, we can still only execute one thread at a time.
Readers/Writer Problem
Let's look at a scenario where there is some subset of threads that want to read from shared state, and one thread that wants to write to shared state. This is commonly known as the readers/writer problem.
At any given point in time, 0 or more readers can access the shared state at a given time, and 0 or 1 writers can access the shared state at a given time. The readers and writer cannot access the shared state at the same time.
One naive approach would be to wrap access to the shared state itself in the mutex. However, this approach is too restrictive. Since mutexes only allow access to shared state one thread at time, we would not be able to let multiple readers access state concurrently.
Let's enumerate the conditions in which reading is allowed, writing is allowed, and neither is allowed. We will use a read_counter and a write_counter to express the number of readers/writers at a given time.
If read_counter == 0 and write_counter == 0, then both writing and reading is allowed. If read_counter > 0, then only reading is allowed. If write_counter == 1, neither reading nor writing is allowed.
We can condense our two counters into one variable, resource_counter. If the resource_counter is zero, we will say that resource is free; that is, available for reads and writes. If the resource is being accessed for reading, the resource_counter will be greater than zero. We can encode the case where the resource is being accessed for writing by encoding resource_counter as a negative number.
Our resource_counter is a proxy variable that reflects the state that the current resource is in. Instead of controlling updates to the shared state, we can instead control access to this proxy variable. As long as any update to the shared state is first reflected in an update to the proxy variable, we can ensure that our state is accessed via the policies we wish to enforce.

Readers/Writer Example
Let's make our previous discussion concrete with an example.

In this example, we can see that our reading and writing operations exist outside of a locked mutex, but are preceded and followed by a mutex enforced update to the shared variable, resource_counter.
Our program will require four things:
resource_counter- a proxy variable for the state of the shared resourcecounter_mutex- a mutex which controls access toresource_counterread_phase- a condition variable signifying that the resource is ready for readingwrite_phase- a condition variable signifying that the resource is ready for writing
Readers can begin reading by first locking the mutex and incrementing the value of the resource_counter. If multiple readers try to lock the mutex at once, all but one will block and each will unblock as the mutex becomes available.
If a writer tries to enter the fray while multiple readers are accessing the state, the writer will have to wait, since our application is such that writes cannot proceed while reads are ongoing. The writer will wait on the condition variable write_phase.
Once the reader decrements resource_counter, it will check to see if resource_counter is zero. If so, that means our application is in a state where writes can proceed, so this final reader will signal on the write_phase variable to wake up a waiting writer. Given that only one writer can proceed at a time, it does not make sense to use a broadcast here.
The pending writer will be removed from the wait queue that is associated with the write_phase variable, and the counter mutex will be reacquired before coming out of the wait operation. We recheck that our predicate (resource_counter != 0) is still true before we adjust resource_counter. We can then proceed with our write.
NB: We need to recheck our condition in our while loop because the act of removing the thread from the wait queue and the act of reacquiring the mutex occur as two separate procedures. This means that the mutex could be reacquired in between these two steps by a different thread, with resource_counter being updated by that thread. Thus, we must check that our condition holds one last time after we acquire the mutex.
If a new thread wants to write while another thread is currently writing, this new thread will have to wait on write_phase. If a new thread wants to read while another thread is currently writing, this new thread will also have to wait, but on read_phase instead.
Once the current writer completes, it resets resource_counter to 0, and then broadcasts to the read_phase and signals to write_phase. We signal to write_phase because only one writer can access the shared state at a given time, and we broadcast to read_phase because multiple threads are allowed to read from the shared state at a given time.
NB: Note that multiple threads cannot access the mutex concurrently, as this defeats the point of the mutex. But, after each thread accesses the mutex in turn, all readers can read from the shared state concurrently. This is why a mutex over the shared state itself was not sufficient: concurrent reads would not have been possible.
Even though we call broadcast before signal we don't really have control over whether a waiting reader or writer will be woken up first. That decision is left up to the thread scheduler, into which we do not usually have insight.
Critical Section Structure
If we consider the reading and writing of the data to be the protected operations of the above application, then those sections of code are really the critical sections of our application, even though they exist outside of a mutex block.
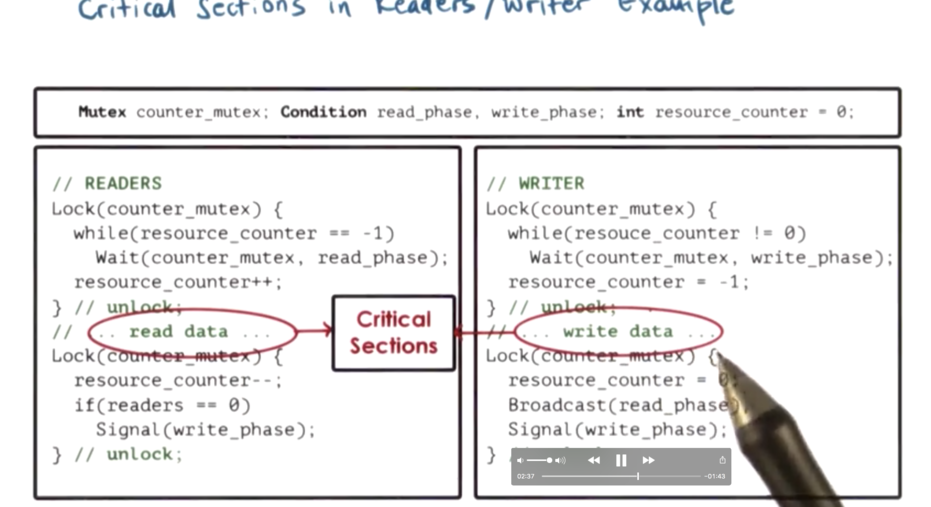
The structure of our application is such that even though the critical operations are not governed by a mutex, entering and exiting from those operations is.

For example, before we can read data, we must first lock the mutex and increment resource_counter. After we read data, we must again lock the mutex and decrement resource_counter. A similar setup exists for writing data.
Each time we acquire the mutex, we must ensure that a condition is met such that we can proceed safely. If the condition is not met, we must wait. Once the condition is met, we can update our proxy variable. If appropriate, we can signal/broadcast to other threads if some condition has changed. Finally we can unlock the mutex.

The "enter critical section" blocks can be seen as a higher level "lock" operation, while the "exit critical section" blocks can be seen as a higher level "unlock" operation, even though a mutex is being locked and unlocked within each of those blocks.

Critical Section Structure With Proxy

Again, this structure allows us to implement more complex sharing scenarios than the simple mutual exclusion that mutexes allow.
Common Pitfalls
Make sure to keep track of the mutex/condition variables that are used with a given shared resource. Comments help!
Make sure to always protect access to shared state, and make sure to do so consistently by acquiring the same mutex. A common mistake occurs when we forget to lock or unlock a mutex associated with a given piece of state. Compilers may generate warnings/errors to help us.
Don't use different mutexes to access a single resource. Using different mutexes to access a resource is akin to just not using a mutex at all, since there is no mutual exclusion amongst different mutexes.
Make sure that you are signaling or broadcasting on the correct condition. Signaling that reads can occur when you should be signaling that writes can occur can impact the correctness of your program.
Make sure to not use signal when broadcast needs to be used. Note that the opposite is actually okay (although it may incur a performance penalty).
Remember that the order of execution of threads is not related to the order in which we call signals or broadcasts. If priority/ordering guarantees are needed, other strategies must be devised.
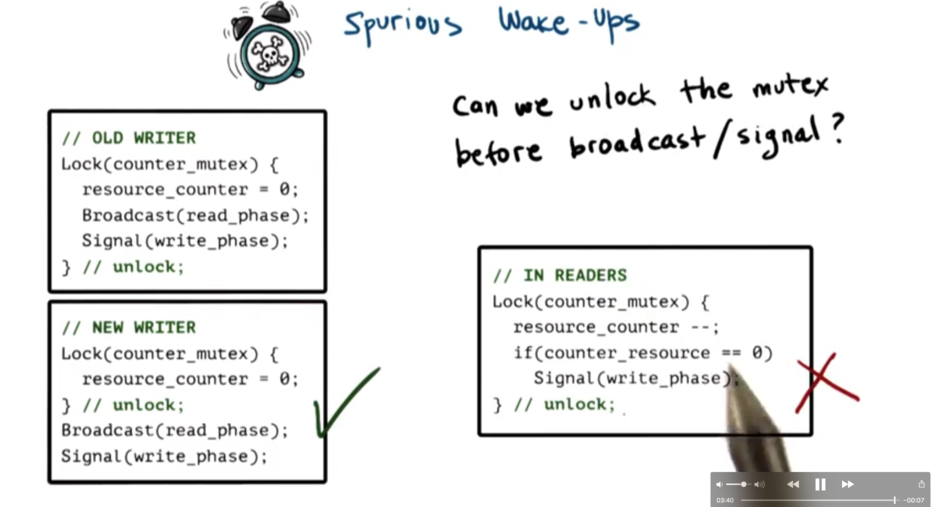
Spurious Wake-ups
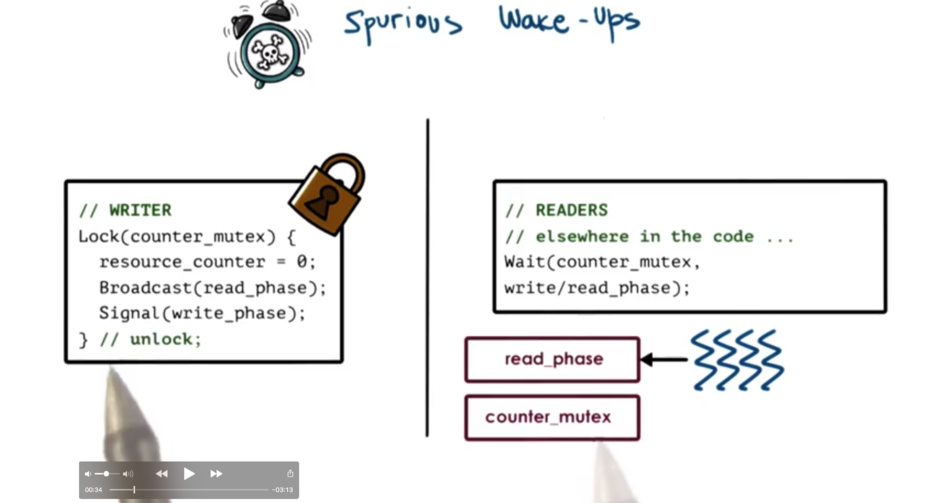
We have a setup similar to the readers/writer example we saw previously. In this case, the writer is locking the mutex after writing to the shared state. Once the mutex is acquired, the proxy variable is updated, and a broadcast and signal are sent.
When the broadcast is issued, the thread library can start removing reader threads from the wait queue for their condition variable, potentially even before the writer releases the mutex.
What will happen, as the readers are removed from this queue is that they will try to acquire the mutex. Since the writer has not yet released the mutex, none of the readers will be able to acquire the mutex. They will have been woken up from one queue (associated with the condition variable) only to be placed on another queue (associated with acquiring the mutex) .
This situation in which we unnecessarily wake up a thread when there is no possible way for it proceed is called a spurious wake up.
Note that spurious wake ups will not affect the correctness of the program, but rather the performance, as cycles will be wasted context switching to threads that will just be placed back on another queue.
Often we can unlock the mutex before we signal or broadcast. Sometimes we cannot. For example, if we signal/broadcast conditionally depending on some property of the shared state, that property must be accessed from within the mutex, which means the signal or broadcast must also take place within the mutex.
Deadlocks
A deadlock occurs when two or more competing threads are waiting on each other to complete, but none of them ever do.
Let's consider two threads, T1 and T2, that need to perform operations on some shared variables A and B. Before performing these operations, each thread must lock the mutex associated with those variables, because they are part of shared state.
Let's assume that T1 first locks the mutex for A and then locks the mutex for B before performing the operation. Let's assume that T2 first locks the mutex for B and then locks the mutex for A, before performing the operation.
This is where the problem lies. T2 will not be able to lock the mutex for A, because T1 is holding it. T1 will not be able to lock the mutex for B, because T1 is holding it. More importantly, neither T1 nor T2 will be able to release the mutex that the other needs, since they are both blocking trying to acquire the mutex the other has.
How can we avoid these situations?
One solution would be to unlock A before locking B. However, this solution will not work in this scenario since we need access to both A and B.
Another solution would be to get all locks up front, and then release all of them at the end. This solution may work for some applications, but may be too restrictive for others, because it limits the amount of parallelism that can exist in the system.
The last and most ideal solution is to maintain a lock order. In this case, we would enforce that all threads must lock the mutex associated with A before locking the mutex associated with B, or vice versa. The particular order may not be important, but rather the enforcement of that ordering within the application is paramount.
A cycle in the wait graph is necessary and sufficient for a deadlock to occur, and the edges in this graph are from the thread waiting on a resource to the thread owning a resource.
We can try to prevent deadlocks. Each time a thread is about to acquire a mutex, we can check to see if that operation will cause a deadlock. This can be expensive.
Alternatively, we can try to detect deadlocks and recover from them. We can accomplish this through analysis of the wait graph and trying to determine whether any cycles have occurred. This is still an expensive operation as it requires us to have a rollback strategy in the event that we need to recover.
We can also apply the ostrich algorithm by doing nothing! We can hope that the system never deadlocks, and if we are wrong we can just reboot.
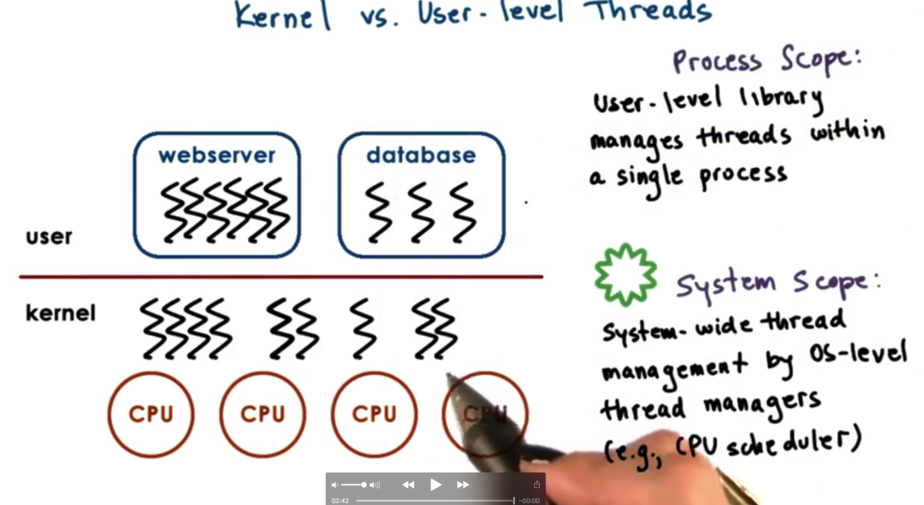
Kernel Vs. User-Level Threads
Kernel level threads imply that the operating system itself is multithreaded. Kernel level threads are visible to the kernel and are managed by kernel level components like the kernel level scheduler. The operating system scheduler will determine how these threads will be mapped onto the underlying physical CPU(s) and which ones will execute at any given point.
Some kernel level threads may exist to support user level applications, while other kernel level threads may exist just to run operating system level services, like daemons for instance.
At the user level, the processes themselves are multithreaded and these are the user level threads. For a user level thread to actually execute, it must first be associated with a kernel level thread, and then the OS level scheduler must schedule that kernel level thread on the CPU.
Multithreading Models
We will consider three multithreading models.
One-to-One Model
In this model, each user level thread has a kernel level thread associated with it. When a user process creates a new user level thread, either a new kernel level thread is created or an existing kernel level thread is associated with this new user level thread.
This means that the operating system can see the user level threads. It understands that the process is multithreaded, and it also understands what those threads need. Since the operating system already supports threading mechanisms to manage its thread, the user libraries can benefit directly from the multithreading support available in the kernel.
One downside of this approach is that is it expensive: for every operation we must go to the kernel and pay the cost of a system call. Another downside is that since we are relying on the mechanisms and policies supported by the kernel, we are limited to only those policies and mechanisms. As well, execution of our applications on different operating systems may give different results.
Many-to-One Model
In this model, all of the user level threads for a process are mapped onto a single kernel level thread. At the user level, there is a thread management library to make decisions about which user level thread to map onto the kernel level thread at any given point in time. That user level thread will still only run once that kernel level thread is scheduled on the CPU by the kernel level scheduler.
The benefit of this approach is that it is portable. Everything is done at the user level, which frees us from being reliant on the OS limits and policies. As well as, we don't have to make system calls for any thread-related decisions.
However, the operating system loses its insight into application needs. It doesn't even know that the process is multithreaded. All it sees is one kernel level thread. If the user level library schedules a thread that performs some blocking operation, the OS will place the associated kernel level thread onto some request queue, which will end up blocking the entire process, even though more work can potentially be done.
Many-to-Many Model
This model allows for some user threads to have a one-to-many relationship with a kernel thread, while allowing other user threads to have a one-to-one relationship with a kernel thread.
The benefit is that we get the best of both worlds. The kernel is aware that the process is multithreaded since it has assigned multiple kernel level threads to the process. This means that if one kernel level thread blocks on an operation, we can context switch to another, and the process as a whole can proceed.
We can have a situation where a user level thread can be scheduled on any allocated kernel level thread. This is known as an unbound thread. Alternatively, we can have the case where a user level thread will always be scheduled atop the same kernel level thread. This is known as a bound thread.
One of the downsides of this model is that it requires extra coordination between the user- and kernel-level thread managers.
Scope of Multithreading
At the kernel level, there is system wide thread management, supported by the operating system level thread managers. These managers will look at the entire platform before making decisions on how to run their threads. This is the system scope.
On the other hand, at the user level, the user level library manages all of the threads for the given process it is linked to. The user level library thread managers cannot see threads outside of their process, so we say that these managers have process scope.
To understand the consequences of having different scope, let's consider the scenario where we have two processes, A and B. A has twice as many user level threads as B.
If the threads have a process scope, this means that the kernel cannot see them, and will probably allocate equal kernel resources to A and B. This means that a given thread in A will be allocated half of the CPU cycles as will be allocated to a thread in B.
If we have a system scope, the user level threads will be visible at the kernel, so the kernel will allocate the CPU relative to the total amount of user threads, as opposed to the total amount of processes. In the case of A and B, if the threads in these processes have a system scope, A will most likely be allocated twice the number of kernel level threads as B.
Multithreading Patterns
Let's discuss three different patterns.
Boss/Workers Pattern
The boss/workers pattern is characterized by having one boss thread and some number of worker threads. The boss is in charge of assigning work to the workers, and the workers are responsible for completing the entire task that is assigned to them.
The throughput of the system is limited by the boss thread, since the boss has to do some work for every task that comes into the system. As a result it is imperative to keep the boss efficient to keep the overall system moving smoothly. Specifically, the throughput of the system is inversely proportional to the amount of time the boss spends on each task.
How does the boss assign work to the workers? One solution is to keep track of which workers are currently working, and send a direct signal to a worker that is idle. This means that the boss must do some work for each worker, since it has to select a worker and then wait for that worker to accept the work.
The positive of this approach is that the workers do not need to synchronize amongst each other. The downside of this approach is that the boss must keep track of every worker, and this extra work will decrease throughput.
Another option is to establish a queue between the boss and the workers, similar to a producer/consumer queue. In this case, the boss is the sole producer, while the workers are consumers.
The positive of this approach is that the boss doesn't need to know any of the details about the workers. It just places the work it accepts on the queue and moves on. Whenever a worker becomes free it just looks at the front of the queue and retrieves the next item.
The downside of this approach is that further synchronization is required, both for the boss producing to the queue, and the workers competing amongst one another to consume from the queue. Despite this downside, this approach still results in decreased work for the boss for each task, which increases the throughput for the whole system.
How many workers?
If the work queue fills up, the boss cannot add items to the queue, and the amount of time that the boss has to spend per task increases. The likelihood of the queue filling up is dependent primarily on the number of workers.
Adding more threads may help to increase/stabilize the throughput, but adding an arbitrary number of threads can introduce complexities.
We can create workers on demand; that is, in response to a new task coming into our system. This may be inefficient, though if the cost of creating a worker (thread) is significant.
A more common model is to create a pool of workers that are initialized up front. The questions remains: how do we know how many workers we ought to create?
A common technique is to use a pool of workers that can be increased in response to high demand on the system. This is not quite like the on demand approach in that new threads will not be created one at a time when the demand passes a threshold, but rather the pool may be doubled or increased by some other multiple.
The benefit of the boss/workers model is the overall simplicity. One thread assigns the work, and the rest of the threads complete it.
One downside of this approach is the thread pool management overhead. Another downside is that this system lacks locality. The boss doesn't keep track of what any of the workers were doing last. It is possible that a thread is just finishing a task that is very similar to an incoming task, and therefore may be best suited to complete that task. The boss has no insight into this fact.
Worker Variants
An alternative to having all the workers in the system perform the same task is to have different workers specialized for different tasks. One added stipulation to this setup is that the boss has to do a little bit more work in determining which set of workers should handle a given task, but this extra work is usually offset by the fact that workers are now more efficient at completing their tasks.
This approach exploits locality. By performing only a subset of the work, it is likely only a subset of the state will need to be accessed, and it is more likely this part of the state will already be present in CPU cache.
In addition, we can offer better quality of service. We can create more threads for urgent tasks or tasks that have higher paying customers.
One downside of this approach is the load balancing mechanisms and requirements may become more difficult to reason about.
Pipeline Pattern
In a pipeline approach, the overall task is divided into subtasks and each of the subtasks are assigned a different thread. For example, if we have six step process, we will have six kinds of threads, one for each stage in the pipeline.
At any given point in time, we may have multiple tasks being worked on concurrently in the system. For example, we can have one task currently at stage one of completion, two tasks at stage two, and so forth.
The throughput of the pipeline will be dependent on the weakest link in the pipeline; that is, the task that takes the longest amount of time to complete. In this case, we can allocate more threads to that given step. For example, if a step takes three times as long as every other step, we can allocate three times the number of threads to that step.
The best way to pass work between these stages is a shared buffer base communication between stages. That means the thread for stage one will put its completed work on a buffer that the thread from stage two will read from and so on.

In summary, a pipeline is a sequence of stages, where a thread performs a stage in the pipeline, which is equivalent to some subtask within the end to end processing. To keep the pipeline balanced, a stage can be executed by more than one thread. Communication via shared buffers reduces coupling between the components of the system.
A key benefit of this approach is specialization and locality, which can lead to more efficiency, as state required for subsequent similar jobs is likely to be present in CPU caches.
A downside of this approach is that it is difficult to keep the pipeline balanced over time. When the input rate changes, or the resources at a given stage are exhausted, rebalancing may be required.
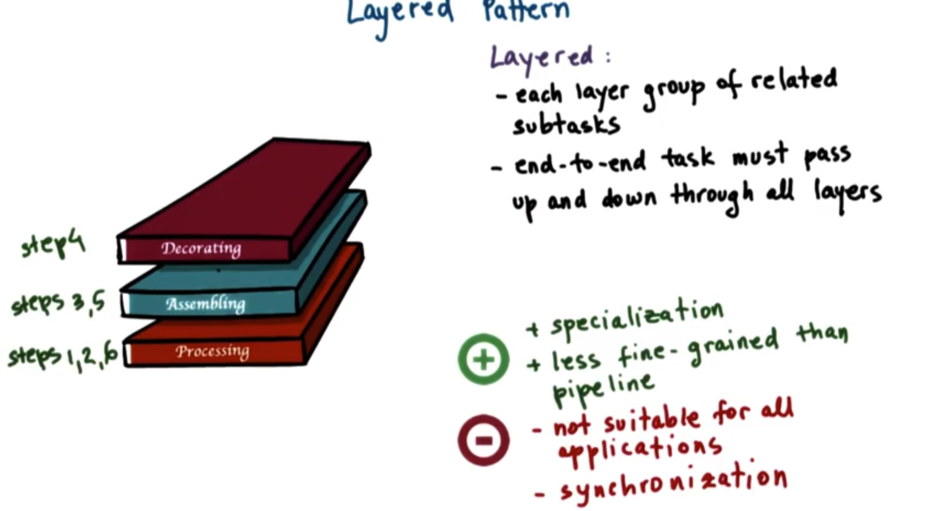
Layered Pattern
A layered model of multithreading is one in which similar subtasks are grouped together into a "layer" and the threads that are assigned to a layer can perform any of the subtasks in that layer. The end-to-end task must pass through all the layers.
A benefit of this approach is that we can have specialization while being less fine-grained than the pipeline pattern.
Downsides of this approach include that it may not be suitable for all applications and that synchronization may be more complex as each layer must know about the layers above and below it to both receive inputs and pass results.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy