Operating Systems
Distributed File Systems
15 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Distributed File Systems
Distributed File Systems
Modern operating systems export a high-level filesystem interface to abstract all of the (potentially) different types of storage devices present on a machine and unify them under a common API.
The OS can hide the fact that there isn't even local physical storage on a machine; rather, the files are maintained on a remote filesystem that is being accessed over the network.
Environments that involve multiple machines for the delivery of the filesystem service are called distributed filesystems (DFS).
DFS Models
A simple DFS model involves clients being served files from a server running on a different machine.
Often, the server is not running on a single machine, but rather is distributed across multiple machines. Files may be replicated across every machine or partitioned amongst machines.
In replicated systems, all the files are replicated and available on every server machine. If one machine fails, other machines can continue to service requests. Replicated systems are fault tolerant. In addition, requests entering a replicated system can be serviced by any of the replicas. Replicated systems are highly available.
In partitioned systems, each server holds only some subset of the total files. If you need to support more files, you can just partition across more machines. In the replicated model, you will need to upgrade your hardware. This makes partitioned systems more scalable.
It's common to see a DFS that utilizes both partitioning and replication; for example, partitioning all the files, and replicating each partition.
Finally, files can be stored on and served from all machines. This blurs the line between servers and clients, because all the nodes in the system are peers. Every node is responsible for maintaining the files and providing the filesystem service. Each peer will take some portion of the load by servicing some of the requests, often those that for files local to that peer.
Remote File Service: Extremes
At one extreme, we have the upload/download model. When a client wants to access a file, it downloads the entire file, performs the modifications and then uploads the entire file back to the server.
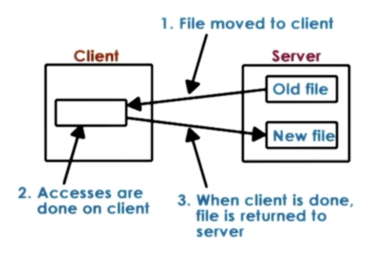
The benefit of this model is that all of the modifications can be done locally, which means they can be done quickly, without incurring any network cost.
One downside of this model is that the client has to download the entire file, even for small modifications. A second downside of this model is that it takes away file access control from the server. Once the server gives the file to the client, it has no idea what the client is doing with the file or when it will give it back.
At the other extreme, we have the true remote file access. In this model, the file remains on the server and every single operation has to pass through the server. The client makes no attempt to leverage any kind of local caching or buffering.
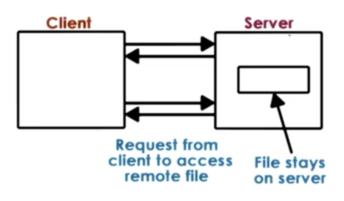
The benefit of this extreme is that the server now has full control and knowledge of how the clients are accessing and modifying a file. This makes it easier to ensure that the state of the filesystem is consistent.
The downside of this model is that every file operations pays a network cost. In addition, this model is limited in its scalability. Since every file operation goes to the server, the server will get overloaded more quickly, and will not be able to service as many clients.
Remote File Service: A Compromise
We should allow clients to benefit from using their local memory/disk and to store at least some part of the file they are accessing. This may include downloading blocks of the file they are accessing, as well as prefetching blocks that they may soon be accessing.
When files can be served from a local cache, lower latencies on file operations can be achieved since no additional network cost in incurred. In addition, server scalability is increased as local service decreases server load.
Once we allow clients to cache portions of the file, however, it becomes necessary for the clients to start interacting with the server more frequently. On the one hand, clients need to notify the server of any modifications they make. In addition, they need to query the server at some reasonable frequency to detect if the files the are accessing from their cache have been changed by someone else.
This approach is beneficial because the server continues to have insight into what the clients are doing and retains some control over which accesses can be permitted. This makes it easier to maintain consistency. At the same time, the server can be somewhat out of the way, allowing some proportion of operations to occur on the client. The helps to reduce load.
The downside with this compromise is that the server becomes more complex. The server needs to perform additional tasks and maintain additional state to make sure it can provide consistency guarantees. This also means that the client has to understand file sharing semantics that are different from what they are used to in a normal filesystem.
Stateless vs Stateful File Server
A stateless server keeps no state.
It has no notion of:
- which files/blocks are being accessed
- which operations are being performed
- how many clients are accessing how many files
As a result, every request has to be completely self-contained. This type of server is suitable for the extreme models, but it cannot be used for any model that relies on caching. Without state, we cannot achieve consistency management. In addition, since every request has to be self-contained, more bits need to be transferred on the wire for each request.
One positive of this approach is that since there is no state on the server, there is no CPU/memory utilization required to manage that state. Another positive is that this design is very resilient. Since requests cannot rely on any internal state, the server can be restarted if it fails at no detriment to the client.
A stateful server maintains information about:
- the clients in the system
- which files are being accessed
- which types of accesses are being performed
- which clients have a file cached
- which clients have read/written the file
Because of the state, the server can allow data to be cached and can guarantee consistency. In addition, state management allows for other functionality like locking. Since accesses are known, clients can request relative blocks ("next kB of data") instead of having to specify absolute offsets.
On failure, however, all that state needs to be recovered so that the filesystem remains consistent. This requires that the state must be incrementally check-pointed to prevent too much loss. In addition, there are runtime overheads incurred by the server to maintain state and enforce consistency protocols and by the client to perform caching.
Caching State in a DFS
Caching state in a DFS involves allowing clients to locally maintain a portion of the state - a file block, for example - and also allows them to perform operations on this cached state: open/read/write,etc.
Keeping the cached portions of the file consistent with the server's representation of the file requires cache coherence mechanisms.
For example, two clients may cache the same portion of file. If one client modifies their local portion, and sends the update to the file server, how does the other client become aware of those changes?
For client/server systems, these coherence mechanisms may be trigged in different ways. For example, the mechanism may be triggered on demand any time a client tries to access a file, or it may be triggered periodically, or it may triggered when a client tries to open a file. In addition, the coherence mechanisms may be driven by the client or the server.
File Sharing Semantics in DFS
Single Node, UNIX
Whenever a file is modified by any process, that change is immediately visible to any other process in the system. This will be the case even if the change isn't pushed out to disk because both processes have access to the same buffer cache.
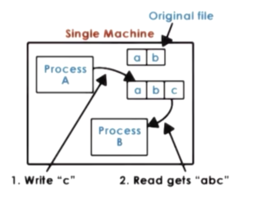
DFS
Even if a write gets pushed to the file server immediately, it will take some time before that update is actually delivered to the file server. It is possible that another client will not see that update for a while, and every time it performs a read operation it will continue seeing "stale" data. Given that message latencies may vary, we have no way of determining how long to delay any possible read operation in order to make sure that any write from anywhere in the system arrives at the file servers so that we can guarantee no staleness.
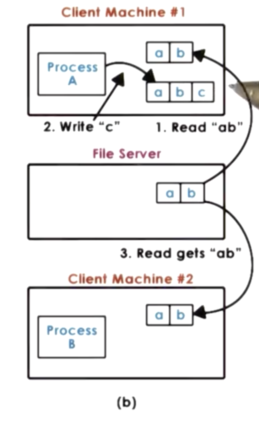
In order to maintain acceptable performance, a DFS will typically sacrifice some of the consistency, and will accept more relaxed file sharing semantics.
Session Semantics
In session semantics, the client writes back whatever data was modified on close. Whenever a client needs to open a file, the cache is skipped, and the client checks to see if a more recent version is present on the file server.
With session semantics, it is very possible for a client to be reading a stale version of a file. However, we know that when we close a file or open a file that we are consistent with the rest of the filesystem at that moment.
Session semantics are easy to reason about, but they are not great for situations where clients want to concurrently share a file. For example, for two clients to be able to write to a file and see each other's updates, they will constantly need to close and re-open the file. Also, files that stay open for longer periods of time may become severely inconsistent.
Periodic Updates
In order to avoid long periods of inconsistency, the client may write back changes periodically to the server. In addition, the server can send invalidation notifications periodically, which can enforce time bounds on inconsistency. Once the server notification is received, a client has to sync with the most recent version of the file.
The filesystem can provide explicit operations to let the client flush its updates to the server, or sync its state with the remote server.
Other strategies
With immutable files, you never modify an old file, but rather create a new file instead.
With transactions, the filesystem exports some API to allow clients to group file updates into a single batch to be applied atomically.
File Vs Directory Service
Filesystems have two different types of files: regular files and directories. These two types of files often have very different access patterns. As a result, it is not uncommon to adopt one type of semantics for files, and another for directories. For example, we have may session semantics for files, and UNIX semantics for directories.
Replication and Partitioning
Fileserver distribution can be accomplished via replication and/or partitioning.
With replication, the filesystem can be replicated onto multiple machines, such that each machine holds all the files.
The benefit of this is that client requests can be load balanced across all machines, which can lead to better performance. In addition, the system overall can be more available. Finally, this system is more fault tolerant. When one replica fails, the other replicas can serve clients with no degradation of service.
The downside of this approach is that writes become more complex. One solution is to force clients to write synchronously to all replicas. Another solution involves writing to one replica, and then having a background job asynchronously propagate the write to the other replicas.
If replicas get out of sync, they must be reconciled. One simple reconciliation technique is voting, where the majority wins.
With partitioning, every machine has a subset of all of the files in the system. Partitioning may be based on filename, file type, directory, or some other grouping.
The main benefit of this approach is that it allows for better scalability as the size of the filesystem grows. With the replicated approach, adding more machines does not mean that you can support a larger filesystem. With the partitioned approach, more machines does mean more files.
As well, writes are simple. Since a single file only lives on a single machine, writes to that file are localized to that machine.
A main downside of this approach is that when a partition goes down, the data stored on that partition can no longer be accessed.
In addition, balancing the system is more difficult, because we have to take into consideration how the particular files are accessed. If there is a particular file that is more frequently accessed by most clients in the system, we can run into the issue of hotspots.
Finally, we can have a solution where the filesystem is partitioned across some axis, and then each partition is replicated some number of times.
Networking File System (NFS) Design
In a Networking File System (NFS), clients access files across the network, hence the name.
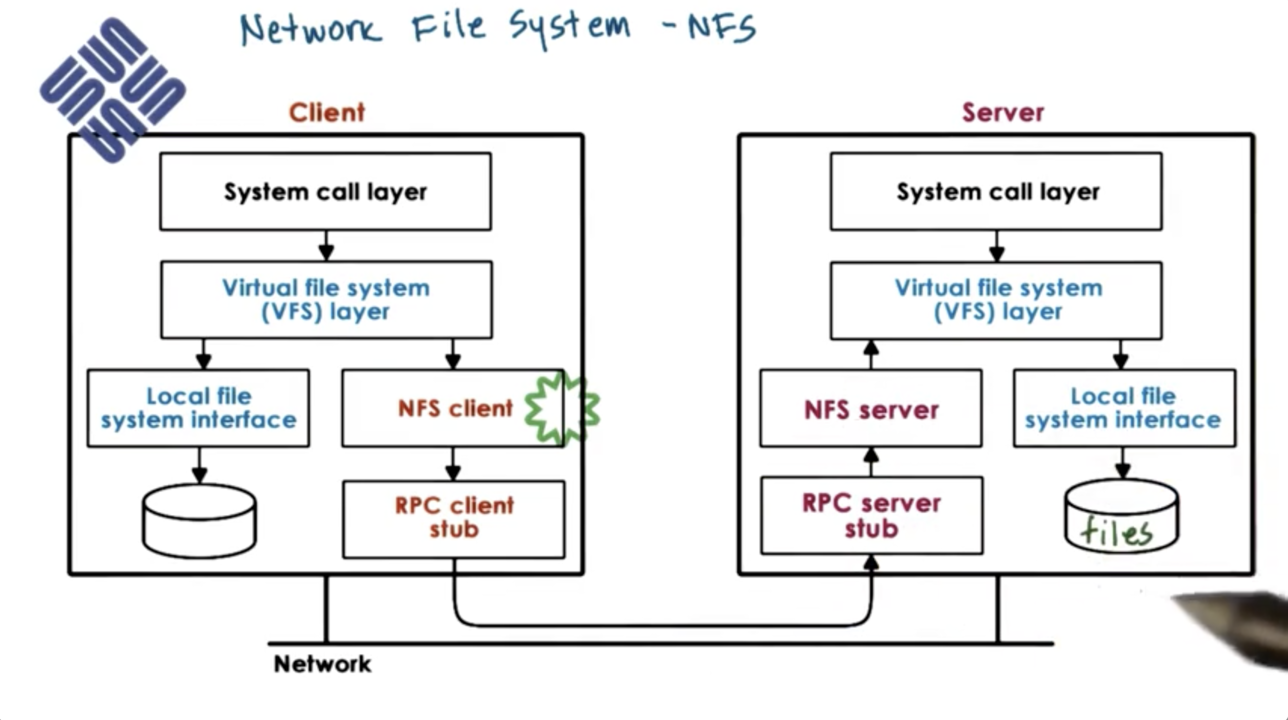
Clients request and access files via the VFS, using the same types of file descriptors and operations that they use to access files in their local storage. The VFS layer determines if the file belongs to the local filesystem or whether the request needs to be pushed to the NFS client so that it can be passed to the remote filesystem.
The NFS client interacts with the NFS server via RPC. The NFS server receives the request, forms it into a proper filesystem operation that is delivered to the local VFS. From there, the request is passed to the local file system interface. On the server machine, requests coming from the NFS server look identical to filesystem requests coming from any other application running on the server machine.
When an open request comes to an NFS server, it will create a file handle. This file handle will contain information about the server machine as well as information about the file. This handle will be returned back to the client machine. Whenever the client wants to access files via NFS, it can pass this handle. If the file is deleted or the server machine dies, this handle becomes stale.
NFS Versions
NFSv3 is stateless, whereas NFSv4 is stateful. Since NFSv4 is stateful, it can support operations like file caching and file locking. Even though NFSv3 is stateless, the implementation typically includes modules that provide certain stateful functionality.
For files that are not accessed concurrently, NFS behaves with session semantics. On close, all of the changes made to a file are flushed to the server, and on open a check is performed and, if necessary the cached portions of the files are updated.
NFS also support periodic updates. Using these updates will break the session semantics when there are multiple clients that are concurrently updating a file.
The periods, by default, are 3 seconds for files and 30 seconds for directories. The rationale is that directories are modified less frequently, and when modified, the changes are more easily resolved.
NFSv4 incorporates a delegation mechanism where the server delegates to the client all rights to manage a file for a given period of time. This avoids the periodic update checks mentioned above.
With server-side state, NFS can support locking. NFS uses a lease-based mechanism to support locking. When a client acquires a lock, the server assigns a certain time period to the client during which the lock is valid. It is then the clients responsibility to either release the lock within the specified time frame or explicitly extend the lock. If the client goes down, the server isn't locked forever.
NFSv4 also supports a reader/writer lock called "share reservation". It also support mechanisms for upgrading from being a reader to a writer, and vice versa.
Sprite Distributed File System
Sprite DFS Access Pattern Analysis
In the paper on caching in the sprite system, the authors performed a study to see how files are accessed in the production filesystem used by their department.
They found that 33% of all file accesses are writes. Caching can be an important mechanism to improve performance: 66% of all operations can be improved. In order to leverage the cache for writes as well, a write-through policy is not sufficient.
Session semantics may have been a good strategy, but the authors also noticed that 75% of files were open less than 0.5 seconds and 90% of files were open less than 10 seconds. This means that the overheads associated with session semantics were still too high.
They also observed that 20-30% of new data was deleted within 30 seconds, with 50% of new data being deleted within 5 minutes. The also observed that file sharing in their system is rare. As a result, the authors decided that write-back on close was not really necessary.
Of course, the authors needed to support concurrent access even though they didn't need to optimize for it.
Sprite DFS from Analysis to Design
The authors decided that Sprite should support caching, and use a write-back policy to send changes to the server.
Every 30 seconds, a client will write back all of the blocks that have not been modified within the last 30 seconds. Note that a file may be opened and closed multiple times by the client before any data is sent to the server.
The intuition behind this is that blocks that have been more recently modified will continue to be modified. It doesn't make sense to force write-backs on blocks that are likely to be worked on more. This strategy avoids sending the same blocks to the server over and over.
Note that this 30 second threshold is directly related to authors' observation that 20-30% of new data was deleted within 30 seconds.
When a client comes along and wants to open a file that is being written by another client, the server will contact the writer and collect all of the outstanding dirty blocks.
Every open operation has to go to the server. This means that directories cannot be cached on the client.
Finally, caching is completely disabled on concurrent writes. In this case, all of the writes will be serialized on the server-side. Because concurrent writes do not happen frequently, this cost will not be significant.
File Access Operations in Sprite
Assume that we have multiple clients that are accessing a file for reading, and one writer client.
All open operations will go through the server.
All of the clients will be allowed to cache blocks. The writer will also have to keep timestamps on each modified block in order to enforce the 30 second write-back policy.
When the writer closes the file, the contents will be stored in the writers' cache. Of course, the next open will still have to go through the server. This means that the server and the client need to keep some sort of version number in order to stay in sync.
On a per file basis, the client keeps track of:
- cache (overall yes/no)
- cached blocks
- timer for each dirty block
- version number
On a per file basis, the server keeps track of:
- readers
- writer
- version
Let's assume that a new writer comes along after the first writer has closed the file. This is referred to as a sequential writer.
In this case, the server contacts the old writer to gather all of the dirty blocks, which is convenient given that the client keeps track of all dirty blocks.
If the old writer has closed the file, the server will update the value of the writer it holds to point to the new writer. At this point, the new writer can proceed and cache the file.
Let's assume that a third writer comes along and wants to write to the file concurrently with the current writer. This is concurrent sharing.
When the write request comes, the server contacts the current writer to gather the dirty blocks. When the server realizes that this writer hasn't closed the file, it will disable the caching of the file for both writers.
To enable/disable caching, it makes sense for the server to maintain a cacheable flag on a per file basis.
Both writers will continue to have access to the file, but all operations will have to go through the server.
When a writer closes a file, the server will see it - as every operation goes through the server - and will make the file cacheable again.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy