Computer Networks Old
Network Security
18 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Network Security
Need for Network Security
The internet is subject to a wide variety of attacks against various parts of the infrastructure.
Attacks on Routing
One of part of the infrastructure that can be attacked is routing. BGP is notorious to being susceptible to various kinds of attacks.
BGP essentially allows any AS to advertise an IP prefix to a neighboring AS and that AS will typically just believe that advertisement and advertise it to the rest of the internet.
The attacks where an AS advertises a route that it does not own are called route hijacks.
For example, on April 8, 2010, China advertised about 50,000 IP prefixes from 170 different countries. The attack lasted for about 20 minutes. In this particular case, the hijack appears to have been accidental because the prefixes were long enough such that they didn't disrupt existing routes.
On February 24, 2008, Pakistan hijacked the Youtube prefixes, potentially as a botched attempt to block Youtube in the country following a government order. Unfortunately, the event resulted in disruption of connectivity to Youtube for people all over the world.
On January 22, 2006, ConEdison accidentally hijacked a lot of transit networks - such as those owned by ISPs - disrupting connectivity for many customers.
On April 25, 1995, AS 7007 advertised all of the IP prefixes on the entire internet as originating in its own AS, resulting in disruption of connectivity for huge fractions of the internet.
Attacks on Naming
Another part of the infrastructure that is vulnerable is naming system, or DNS.
One very popular and effective means of mounting an attack on the naming system is through reflection. DNS reflection is a way of generating very large amounts of traffic targeted at a victim, and is often used in distributed denial of service (DDoS) attacks.
In a phishing attack, an attacker exploits DNS in order to trick a user into revealing personal information - such as passwords - on a rogue website.
Internet is Insecure
The internet's design is fundamentally insecure. Many explicit design choices have caused the internet to be vulnerable to different types of attacks.
The internet was designed for simplicity. Security was not a primary consideration when the internet was designed.
In addition, the internet is "on by default". In other words, when a host is connected to internet, it is by default reachable by any other host that has a public IP address.
This "on by default" model wasn't an issue when the internet consisted of a small number of trusted networks, but as the internet continued to grow, the model has come under fire.
Part of the reason that model doesn't work is because hosts are insecure. This makes it possible, and sometimes easy, for a remote attacker to compromise a machine that is connected to the internet and commandeer it for purposes of attack.
In many cases, an attack might just look like normal traffic. For example, in the case of an attack on the victim web server, every individual request to that web server might look normal, but the collection of requests together - mounted as a DDoS attack - might add up to a volume of traffic that the server is unable to handle.
Finally, the internet's federated design obstructs cooperation, diagnosis, and mitigation. Because the internet is run by tens of thousands of independent networks, it can be very difficult to coordinate a defense against an attack because each network is run by different operators, sometimes in completely different countries.
Resource Exhaustion Attacks
One of the internet's fundamental design tenets is packet switching.
In a packet-switched network, resources are not reserved, and packets are self-contained: each packet has a destination IP address and travels independently to the destination host.
In a packet-switched network, a link might be shared by multiple senders at any given time using statistical multiplexing.
One drawback of this design is that a large number of senders can overload a resource, like a node or a link.
This type of attacks is referred to as a resource exhaustion attack.
Circuit-switched networks - such as the phone network - do not have this problem. Since every connection effectively has allocated dedicated resources, there is no way to overload the network.
Components of Security
Resource exhaustion attacks a basic component of security known as availability, or the ability to use a resource.
In addition to availability, we would like the network to provide confidentiality. If you are performing a sensitive transaction, like a bank transfer, you'd like the internet to conceal the details of that transaction.
Another component of security is authenticity. Authenticity assures the identity of the origin of a piece of information. For example, if you are reading a news article, you'd like to be assured that it really came from the source it claims.
A third component of security is integrity. Integrity prevents unauthorized changes to information flowing through the network.
Threat vs. Attack
A security threat is anything that might cause a violation of one of these security properties, while an attack is an action that results in the violation of one of these security properties.
Confidentiality and Authenticity Attacks
One attack on confidentiality is eavesdropping, whereby an attacker might gain unauthorized access to information being sent between two parties.
For example, if Alice and Bob are sending email between one another, there is a potential - a threat - that Eve might be able to hear that communication.
There are various packet sniffing tools, such as Wireshark and tcpdump, that set a machine's network interface card into promiscuous mode.
If Eve has her network card in promiscuous mode, she might be able to hear some of the packets that are flooded on the local area network and, if she is on the same LAN as Alice and Bob, some of those packets may be for their communication.
It's worth thinking about how different types of traffic might reveal important information about communication.
The ability to see DNS lookups would provide the attacker information about what websites you are visiting. The ability to capture packet headers might give the attacker information about what types of applications you are using. The ability to capture a full packet payload would allow an attacker to effectively see everything you are sending on the network.
Given the ability to see a packet, Eve might not only listen to that packet, but might also modify it, and re-inject it into the network. If Eve can do this, and suppress the original packets from Alice, she can effectively impersonate Alice.
This is referred to as a Man in the Middle attack.
Negative Impact of Attacks
These attacks can have serious negative effects, including
- theft of confidential information
- unauthorized use of network bandwidth
- spread of false information
- disruption of legitimate services
Routing Security
Our focus on routing security will primarily look at inter-domain routing, and the security of BGP.
We will further focus on control plane security, which typically involves authentication of the messages being advertised by the routing protocol.
The goal of control plane security is to determine the veracity of route advertisements, and there are various aspects of the routing protocol that we seek to verify.
Session authentication protects the point to point communication between routers. Path authentication protects the AS path. Origin authentication protects the origin AS in the AS path, effectively guaranteeing that the origin AS advertising a prefix is actually the owner of that prefix.
Route Attacks
Route attacks can arise in various different ways.
For example, the router can simply be misconfigured. In this case, the false route advertisement is no intended. The AS7007 attack was actually the result of a configuration error.
Alternatively, the router might actually be compromised by an attacker. Once this happens, the attacker can reconfigure the router to advertise false routes.
Unscrupulous ISPs might also decide to purposely advertise routes that they shouldn't be advertising.
To launch a route attack, an attacker might reconfigure the router or tamper with the management software that changes the configuration. They might also tamper with software or actively modify the routing message.
The most common attack is a route hijack attack, which is an attack on origin authentication.
Route Hijacking
Suppose that you would like to visit a particular website.
To do so, you'd first need to issue a DNS query which traverses the hierarchy of DNS servers to find the authoritative nameserver for the website's domain name and thus the IP address associated with that domain name.
Ultimately, this authoritative nameserver has its own IP address, advertised via BGP like any other IP address.
If an attacker was using a rogue DNS server and wanted to hijack your DNS query to return a false IP address, they might use BGP to advertise a route for the IP prefix that contains the authoritative DNS server.
The problem with a route hijack attack like this is that all traffic destined for the hijacked IP address is going to head to the attacker, including the traffic from the legitimate network.
What we'd like to have happen instead is for traffic to first go to the rogue location and then pass through to the legitimate location, effectively making the attacker a man in the middle.
In order to do this, the attacker needs to somehow disrupt the routes to the rest of the internet while leaving the routes between the spoofed and authentic location intact.
Example
Suppose the AS 200 originates a prefix and the paths that result from the original BGP routing below.
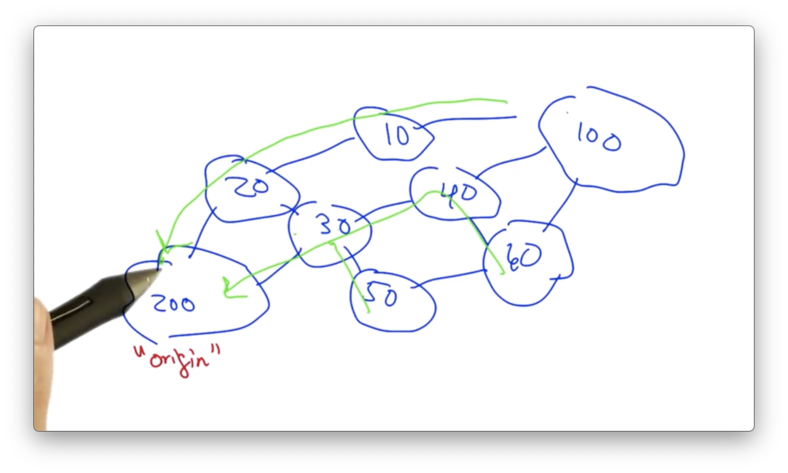
Now suppose that AS 100 seeks to become a MITM. If the original prefix being advertised was P, AS 100 could also advertise P.
We need to ensure that AS 100 maintains a path back to AS 200. This path already exists through AS 10 and AS 20, so we need to make sure that neither AS 10 nor AS 20 accept this hijacked route.
We can accomplish this by using AS path poisoning.
AS 100 will advertise a route that includes AS 10 and AS 20 in the AS path. Both of these ASes will drop the announcement because they will think that they already heard the announcement and won't want to form a loop.
Every other AS not on the path back from 100 to 200 will switch.
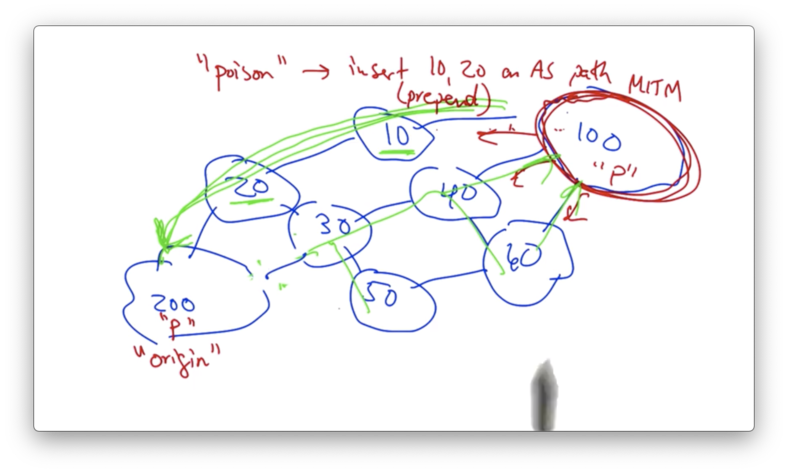
Now all of the traffic en route to AS 200 will traverse AS 100.
A traceroute might look funny taking this circuitous route, but the attacker can hide its presence even if the attacker is running traceroute.
traceroute simply consists of ICMP time-exceeded messages when a packet reaches a TTL of 0.
Typically each router along a path will decrement the TTL at each hop.
If the routers in the attacker's network never decrement the TTL, no time-exceeded messages will be generated by routers in AS 100.
As a result, traceroute would never show AS 100 on the path at all.
Autonomous System Session Authentication
Session authentication attempts to ensure that BGP routing messages sent between routers on adjacent ASes are authentic.
Since the session between ASes is a TCP session, the authentication can be done using TCP's MD5 authentication option.
In such a setup, every message exchanged on the TCP connection not only contains the message but also a hash of the message with a shared secret key.
The distribution of this key is manual. The operator in each AS must agree on a key, which is typically done out of band - for example, over the phone.
Once that key is set within the router configuration, all messages between the adjacent routers is authenticated.
Another way to guarantee session authentication is to have AS 1 transmit packets with a TTL of 255 and have the AS 2 drop any packet that has a TTL less than 254.
Because most eBGP sessions are only a single hop and attackers are typically remote, it is not possible for the recipient AS to accept a packet from the attacker because the attacker's packet will have a TTL less than 254.
Origin and Path Authentication
There is a proposal to modify the existing border gateway protocol to add signatures to various parts of the route advertisement, which can help provide origin and path authentication .
This proposal is sometimes called Secure BGP (BGPSEC), and has two parts.
First, there is an origin attestation, which is a certificate the binds the IP prefix to the organization that owns that prefix, including the origin AS. This is sometimes called an address attestation.
The certificate must be signed by a trusted party, such as a routing registry or the organization that allocated that prefix to the AS in the first place.
The second part of BGPSEC is a path attestation. These are a set of signatures that accompany the AS path as it is advertised from one AS to the next.
Autonomous System Path Attestation
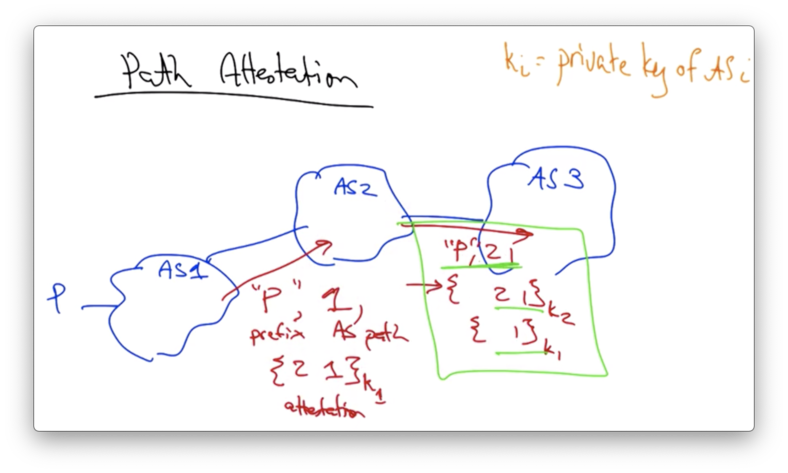
Let's assume that we have a path with three ASes, and AS 1 wants to advertise prefix P.
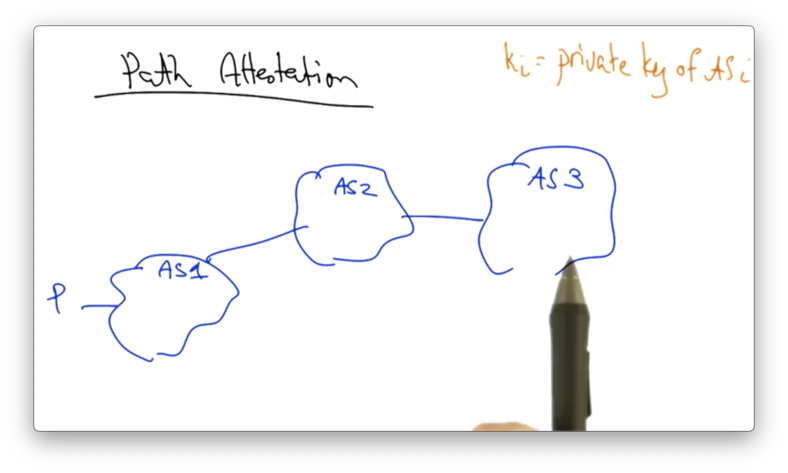
Each AS also has a private/public key-pair. An AS can sign a route with its own private key, and any other AS can check that signature with the signing AS's public key.
The BGP announcement from AS 1 to AS 2 will contain the prefix P as well as the AS path, which so far is just 1.
This announcement will also contain the path attestation - the path 2 1 - which is signed with the private key of AS 1.
When AS 2 re-advertises the route announcement to AS 3, it advertises the new AS path 2 1.
It adds its own route attestation, 3 2 1 signed by its own private key, and it also includes the original path attestation, signed by AS 1.
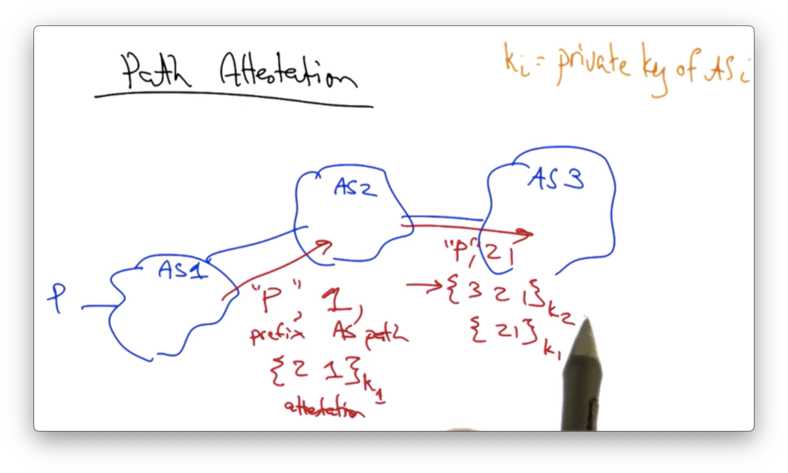
A recipient of a route along this path can thus verify every step of the AS path.
For example, AS 3 can use the first part of the path attestation to verify that the path goes from AS 2 to AS 1 and does not contain any other ASes in between.
AS 3 can use the second part of the path attestation to ensure that the path between it and the next hop is AS 2, and that no other ASes could have inserted themselves between AS 2 and AS 3.
This is precisely why the AS signs a path attestation with not just its own part of the AS path but also includes the AS that is intended to receive the advertisement.
To see the importance of this inclusion, let's suppose that these next hop ASes were not present in path attestations.
If this were the case, an attacker (AS 4) could claim it was connected to P via AS 1, when no such link exists, simply by replaying only the path attestation 1, signed by AS 1.
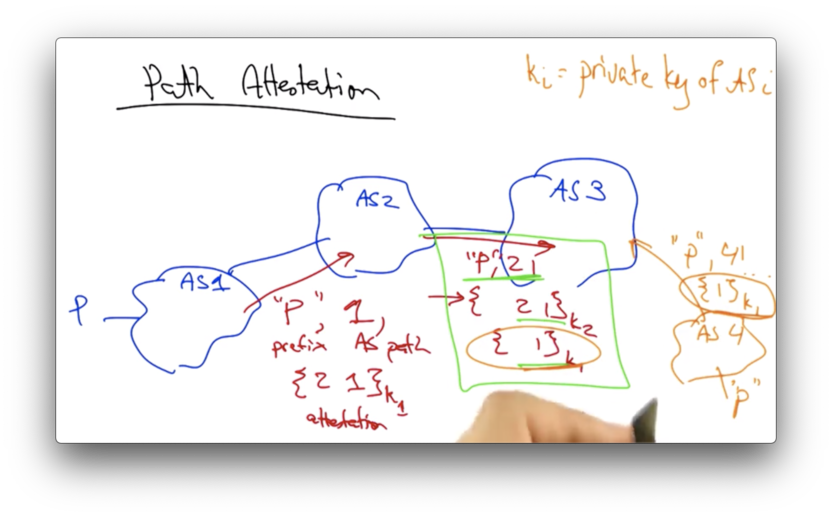
In reality, however, AS 1 never generates this signature. It generates the signature 2 1. In order to accurately spoof the path attestation, AS 4 would have to generate the attestation 4 1, signed by AS 1.
AS 4 cannot create this attestation, because it cannot forge AS 1's signature as it does not own AS 1's private key.
This is the reason why each AS signs a path attestation with not only its own AS in the path, but also the next AS along the path.
Unfortunately, path attestation does not prevent against all types of attacks. If an AS fails to advertise a route or a route withdrawal, there is no way for the path attestation to prevent that.
Path attestation can also not defend agains certain types of replay attacks, such as a premature re-advertisement of a withdrawn route.
Finally, there is no way to guarantee that the data traffic actually travels along the advertised AS path, which is a significant weakness of BGP that has yet to be solved by any routing protocol.
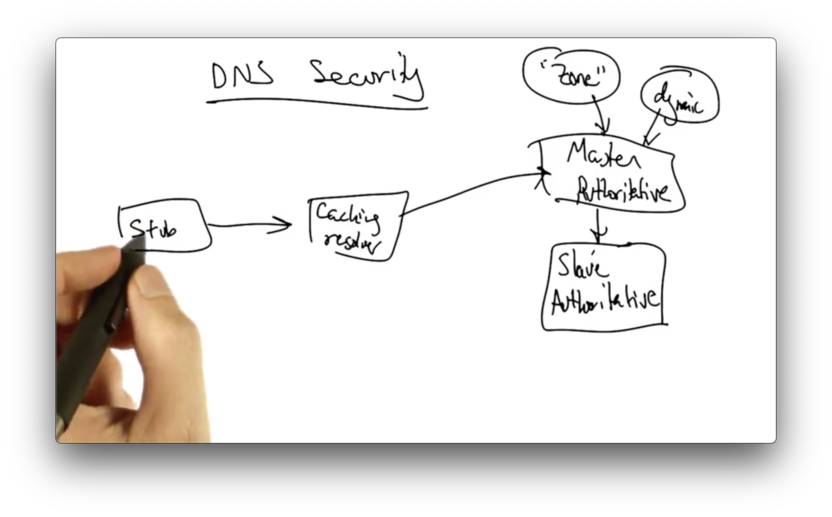
DNS Security
To understand the threats and vulnerabilities of DNS, we first need to look at the DNS architecture.
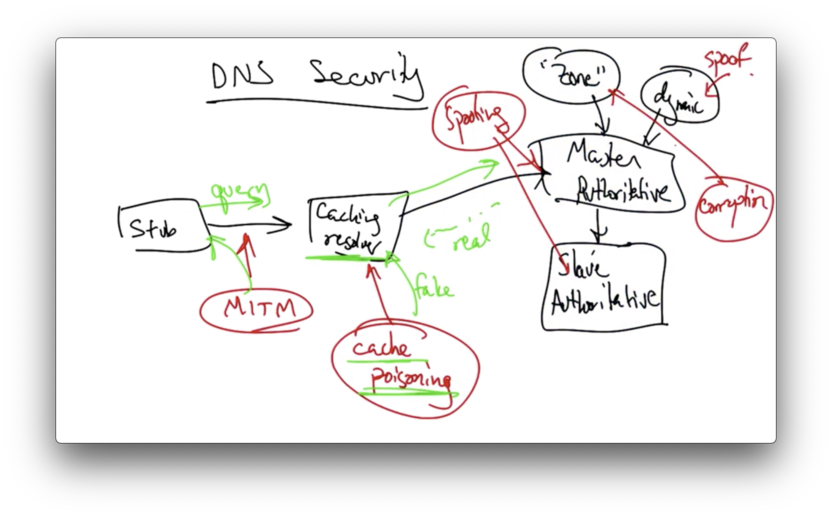
We could have a man in the middle attack positioned between the stub resolver and the caching resolver, whereby an attacker observes a query and forges a response.
If the caching resolver issues a query to the authoritative nameserver, an attacker could try to send a reply back to the caching resolver before the real reply comes back, in an attempt to poison the cache with bogus DNS records for a particular name.
This is called cache poisoning and is particularly virulent.
In addition, master and replica name servers can be spoofed. Zone files can be corrupted and updates to the dynamic update systems can also be spoofed.
Why is DNS Vulnerable?
The fundamental reason for the vulnerability of DNS is that basic DNS protocols have no means of authenticating responses received by resolvers.
Resolvers trust the responses they receive, which means that if an attacker is able to send a reply to a query faster than a legitimate DNS server, the resolver is likely to believe the attacker.
A secondary reason that these types of spoofed replies are possible is that DNS queries are typically connectionless, using UDP instead of TCP at the transport layer. As a result, a resolver does not have a reliable way of mapping the query it sends to the response it receives.
DNS Cache Poisoning
Consider a network where a stub resolver issues a query to a recursive resolver and the recursive resolver sends the query to the start of authority (SOA) for that domain.
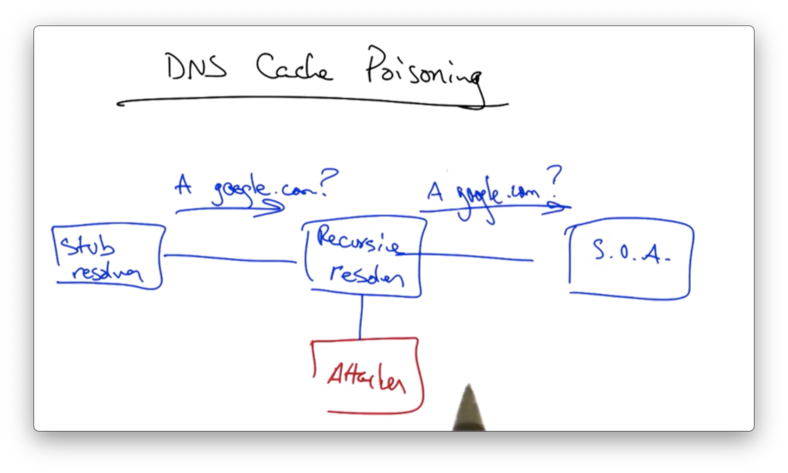
In an ideal world, the authoritative nameserver for that domain would reply with the correct IP address.
If an attacker guesses that the recursive resolver may need to eventually issue a query for a site like google.com, the attacker can simply send the resolver multiple, specially crafted replies, each with a different ID.
Even though the query has some query ID, the attacker doesn't need to see that ID because they can simply flood the resolver with a bunch of bogus replies, each containing a different ID, and one of them will eventually match.
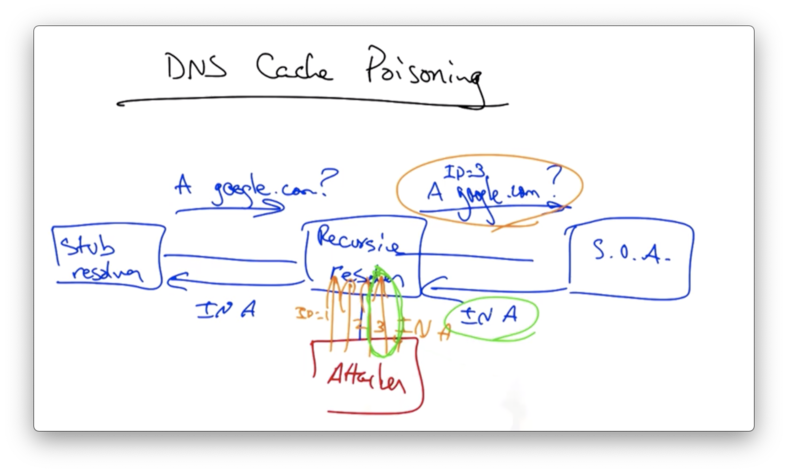
As long as the bogus response reaches the resolver before the legitimate response, the recursive resolver will accept the bogus message and will cache it.
Since DNS has no way to expunge a cached message, the recursive resolver will continue to send bogus responses for any A record query for this domain name until that entry expires from the cache.
There are several defenses against cache poisoning.
Using a query ID is a defense, although a rather weak one, because it can be guessed. Naturally, the next defense is to randomize the ID instead of sending queries where the IDs increment in sequence.
This makes the ID tougher to guess, but since the ID is only 16 bits, an attacker only has to flood the recursive resolver with potentially thousands of responses.
To make matters worse, due to the birthday paradox, the probability that such an attack will succeed using only a few hundred replies is relatively close to 1.
The attack does not need to send replies with all 32,000 IDs.
The success of a DNS cache poisoning attack depends not only on the ability to reply to a query with the correct query ID.
It also depends on "winning the race"; that is, the attacker must reply to the query before the legitimate authoritative nameserver. If the attacker loses the race, then they have to wait for the cached entry to expire before trying again.
However, the attacker could generate their own DNS queries to send to the resolver. For example, the attacker could query 1.google.com, 2.google.com, and so forth.
Each one of these bogus queries will generate a new race, and eventually the attacker will win one of those races for an A record query.
Of course, the attacker doesn't actually want to own 1.google.com, they want to own all of google.com.
The trick here is that instead of responding with just A records in the bogus replies, the attacker can also respond with NS records, for the entire zone of google.com, essentially making them the SOA for all of Google.
This particular flavor of cache poisoning attack is referred to as a Kaminsky attack, after security researcher Dan Kaminsky.
DNS Cache Poisoning Defense
In addition to having a (potentially randomized) query ID, the resolver can randomize the source port on which it sends the query, thereby introducing an additional 16 bits of entropy to the ID associated with the query.
Unfortunately, picking a random source port can be resource intensive and using a NAT could de-randomize the port selection.
Another defense is 0x20 encoding, which is based on the intuition that DNS matching and resolution is entirely case insensitive. The 0x20 bit, which affects whether a particular character is capitalized, can be used to introduce additional entropy.
When generating a response to a query, the queried domain name is copied directly from the query into the response. If the resolver sends www.GoOGle.com, the authoritative server will reply with www.GoOGle.com.
If the resolver and the authoritative server can agree on a shared key by which the capitalization scheme of the domain name is derived, then the resolver and the authoritative server can validate/enforce the capitalization of domain names passed between them.
As a result, it becomes even more difficult for the attacker to inject a bogus reply, because now the attacker has to guess the capitalization sequence for any particular domain name in addition to the query id.
DNS Amplification Attacks
DNS amplification attacks exploit the asymmetry in size between DNS queries and responses.
An attacker might send a DNS query for a particular domain, which might be only 60 bytes. In sending the query, the attacker might indicate that the source address for this query is some victim IP address. The resolver will then send the reply - nearly two orders of magnitude larger at ~3000 bytes - to the victim.
By generating a small amount of initial traffic, the attacker can cause the DNS resolver to generate a significantly larger amount of attack traffic.
If we start adding other attackers, we can likely create a denial of service attack on the victim.
Possible defenses against this type of attack include preventing IP address spoofing by using appropriate filtering rules and disabling the ability of a DNS resolver to resolve queries from arbitrary locations on the internet.
DNSSEC DNS Security
One of the major reasons for DNS's vulnerabilities is the lack of authentication.
The DNSSEC protocol adds authentication to DNS responses by adding signatures to the responses that are returned for each DNS reply.
Consider the following DNS traversal for google.com. For the sake of the example, assume there is no caching involved.
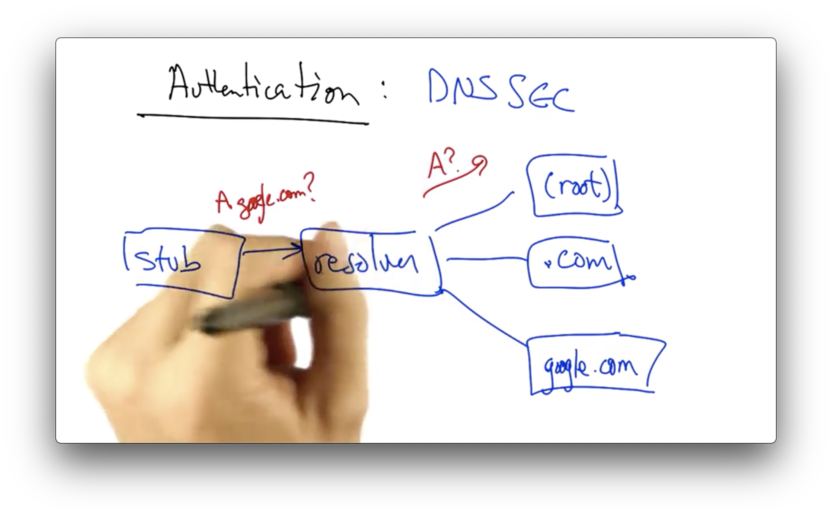
When a stub resolver issues a query, the query is relayed by the recursive resolver to the root nameserver.
The root name server sends a referral to the .com nameserver, and this referral includes the signature - by the root - of the IP address and the public key of the .com nameserver.
As long as the resolver knows the public key corresponding to the root nameserver, it can check the signature and verify that the referral is to the correct IP address for .com nameserver.
In the process, the resolver also learns the public key corresponding to the .com nameserver.
Thus, when the .com nameserver sends the next referral to google.com nameserver, that referral is signed by the .com nameserver's private key.
Since the root nameserver had relayed the public key associated with the .com nameserver, the resolver can verify the referral from the .com nameserver.
Similarly, the .com nameserver will return not only the IP address for google.com nameserver, but also the signed IP address and public key for the google.com authoritative nameserver.
In summary, each authoritative nameserver in the DNS hierarchy returns not only the referral but also a signature containing the IP address for that referral and the public key for the referred authoritative nameserver. This allows the resolver to verify signatures at the next lowest level of the hierarchy until we finally get the answer.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy